When creating models to trade the markets we generally attempt to find mathematical relationships that describe financial time series in order to be able to make predictions that are accurate enough to obtain a monetary gain. These models generally have no fundamental insight but are instead guided by empirical observations that we make from price series, with no hope to derive the price series itself from first principles. On today’s post I want to talk to you about the issues that stem from this approach as well as how we could possibly overcome it to gain a deeper insight into financial markets. First I will go through some analogies that best describe what we attempt to do when developing quantitative trading models and I will then talk about how I would envision a model that is rid of these problems.
–
–
For a moment lets imagine that you have no idea how gravity works and you are attempting to predict how a bouncing ball will move after being thrown. Since you have no insight into the fundamental mechanism that drives the ball’s movements – gravity in this case – you will make observations and come up with equations that best describe the movement of the ball given some parametric inputs. After 100 trials you now have a model where you can input the ball’s initial conditions – things like the speed, mass of the ball and height from which it is thrown – that help you predict where the ball will finally land. You now have an empirical model for a bouncing ball that has no idea of why the ball does what it does but can tell you, for a given set of initial conditions A, expect B.
After this you then test your model on 100 new trials and you realize that your predictions are way off in some cases. You then decide to update your model to account for the new data and you then get a new model. While model 2 is expected to be much better able to draw accurate predictions of bouncing ball movements than model 1 it still has no idea of why the ball behaves the way it does. It is therefore easy to realize that the more observations you get the more accurate your model will be in terms of making predictions but there will always be predictions you are unable to properly make – because your model is curve-fitted to your past observations – and you will only reach a fully accurate model when the number of observations approaches infinity. As Aristotle would say, the only way in which you can draw a certain prediction is if you have made all possible observations.
–

–
When we attempt to predict the markets using normal quantitative models we are doing the same thing. We have a certain set of market data that we use to create a model that we know can make accurate predictions within that set, we then extrapolate to future observations and discard models that fail. As new data comes in we create new models and we repeat the process for as long as we want to make money. If we have enough data to account for a large enough set of market behavioral patterns and we keep on creating new models with incoming new data it is expected that we will be making money for as long as we can find new models that fit all known market behaviors. This is the basis of all our machine learning and price action based mining efforts.
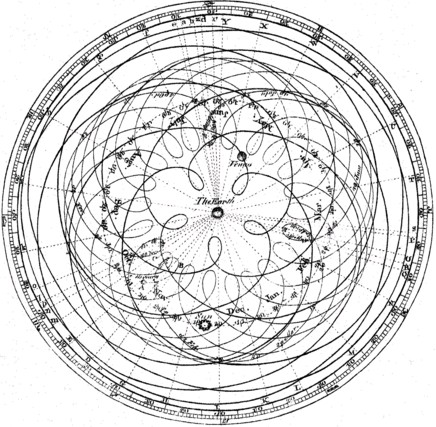
However the above poses an interesting question. What do we expect these models to become? History teaches us that when pure empirical observations with a lack of insight are made we get models that become more and more complex with time (this does not mean they will stop making money!). As the number of observations increases so does model complexity. Consider the case of the Ptolemaic epicycles where describing the retrograde movement of the planets generated extremely convoluted models that could draw predictions that were accurate but within models that were extremely complicated. In analogy you could have tremendously complicated models that are able to draw accurate enough predictions of the market – models that make money – but which are only expected to become more complicated as the number of observations increases. There is certainly nothing wrong with this – it is something many of us use to make money trading the markets – but I like to believe we can go further.
The solution to the above is coming up with market models from first principles that make deep insights into the nature of the financial markets. Just as Kepler destroyed the Ptolemaic model with the simple realization that planetary orbits were ellipses around the sun so can a market model that can draw predictions from first principles provide a fundamental increase in our understanding of the markets with a tremendous gain in model simplicity. Understanding the markets has some fundamental gains beyond the simple fact that you can make money from it. Deep insights into how human behavior generates the OHLC charts you see can help us better understand ourselves and the world around us. It can lead to great improvements into how monetary and fiscal policy is carried out and how these changes are expected to affect us.
–

–
There are many people who have attempted to do the above. There is an important accumulation of knowledge into how this works – especially in the area of behavioral economics – and I will attempt to go deeper into this subject into future posts to show you how we can start to construct market models that are not typical regression based algorithms (fits to empirical observations) but rather models that are based on true insights into human behavior and market composition. If you would like to learn more about model building and how you to can construct your own quantitative models using mining software please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general.




