Our data-mining efforts to automatically build trading systems have been using machine learning methods through most of this year. Although we have had some set backs as we implement and debug our data-mining implementation we now have a rather solid setup that uses several different machine learning algos and can use the power of GPU mining to explore huge spaces and machine learning algorithm ensembles. However so far we hadn’t been able to implement random forest algorithms as the computational cost of the available implementations seemed to be too high. Today I am going to talk about why this algorithm type is interesting and how I finally managed to add this to our machine learning possibilities using some simple tricks.
–
–
Statistically speaking random forests are a type of ensemble learning method. In random forests you construct decision trees that use relationships between input and output variables and in the end you use the resulting prediction from a significant number of trees to get your result. In random forests the branching in trees is decided by randomly selecting from the available inputs and in the end a forest of N trees, each with a potentially different construction, is used to arrive at an end result. Being an ensemble method random forests have a lot of statistical power and can yield useful predictions where other methods fail to find something useful.
Random forests have several advantages over other machine learning algorithms. They allow for the construction of non-linear relationships – just like Neural Networks can do – but they are very efficient at eliminating useless variables: they alleviate the curse of dimensionality. While Neural Networks have a very hard time when you include useless information in the model – noise generally makes predictions much worse – in random forests this problem is much smaller due to the way in which the ensemble model is constructed. Of course random forests are not rid of defects and they can suffer from problems when there are imbalances in the input set – for example you want to classify between two categories but have two examples of one and 90 of the other – reason why their adequate performance usually depends on the training data being somewhat balanced.
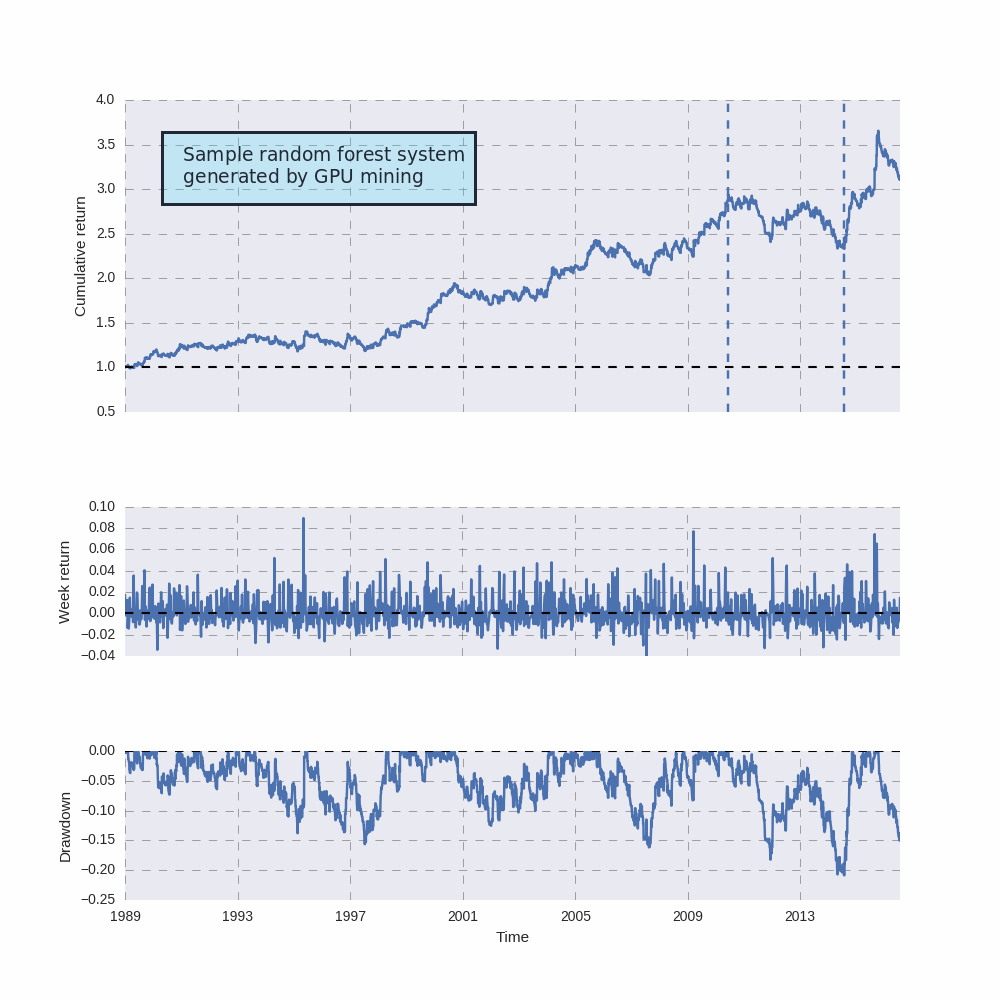
Using random forests for mining had always been something I wanted to do but doing this was difficult since the use of random forests – even in the Shark C++ library – was prohibitively expensive because of the amount of simulations we had to carry out. Our systems train using a moving window before making any trading decision so using a random forest involved thousands of expensive training steps per simulation. Then I noticed how the number of trees in Shark is set to a value of 100 by default, which makes the evaluation terribly expensive since 100 decision trees need to be constructed. This was also unnecessary given that the amount of inputs we generally use for prediction are small (2-10 normally) reason why it seemed reasonable to decrease the number of trees within the model to a value that was adequate given the characteristics of the training datasets we usually use in simulations. Reducing the number of variables that are randomly tried at each branch from 3 to 2 was also possible.
With the above implementations I was able to take the number of trees down from 100 to 10 – without compromising the accuracy of results – and I was able to reduce execution time by around 10x. This allowed me to finally use random forests in mining exercises that search for systems where models are constantly retrained after each bar. Although the random forests are yet to be used in our community mining – an update including them will be released this Wednesday at Asirikuy – I have already mined a few sample systems to make sure that everything was working properly. A curve for such a system is showed above, showing that random forests can indeed lead to usable strategies. This system was however mined with a low Sharpe filter – to generate a result quickly – in reality we will mine for systems with better statistical characteristics.
–

–
Another important thing is that despite the fact that the method is non-deterministic in nature – model initialization and construction has a strong random component – given the number of trees and inputs I always obtain the same results when back-testing these strategies. This is another advantage of the changes in variables I carried out which is essential for the mining of machine learning strategies. If you would like to learn more about our machine learning mining efforts and how too can trade a portfolio based on strategies that constantly retrain their machine learning models before each trading decision please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.strategies




