Although my efforts in building machine learning systems for the Forex market were initially centered on building systems for the daily time frame using non-linear regression methods (mainly neural networks) I have been moving towards the building of machine learning systems on the lower time frames using a more varied arsenal of algorithms during the past year. This is both because building of historically profitable systems on the daily time frame for instruments besides the EUR/USD was never achieved successfully and because I wanted to explore other classification and regression techniques that might me much more computationally cheap. Since the building of systems that constantly retrain on the lower time frames generally demands a much larger number of bars, using methods that are computationally cheaper makes more sense. However during the past few months I have been hitting a road-block in the building of these systems, mainly due to issues related with the broker dependency. Through the rest of this post I will explain to you what my problems have been and how I have attempted to tackle them in order to generate robust machine learning methodologies.
–
–
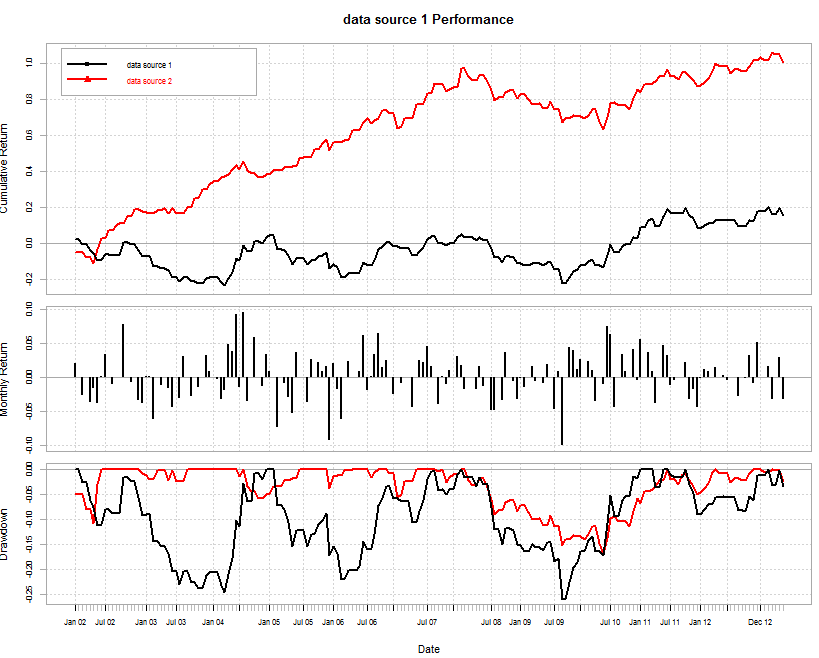
A few months ago I was eager to write about the building of historically profitable systems trading on the lower timeframes across several Forex symbols using constantly retrained machine learning techniques. As a matter of fact I later refined this methodology enough such that I am now able to generate historically profitable results on all Forex majors during the past 25 years of data, using simple ensembles of classifiers on the 1H timeframe (systems with high linearity and very decent profit to drawdown characteristics). The systems retrain their models on every new hourly candle and make use of simple trade management mechanisms (such as trailing stops) to further enhance their profitability. When I had generated a portfolio of systems to trade across all FX majors and I was ready to move them to live trading I decided to run a final test which sought to evaluate feed dependency, so I used data from a separate broker (different from my 25 year data source), to see the results.
I was quite shocked to see that results were not only completely different but profitability was obliterated. In the graph above you can see the 2002-2012 period evaluated on both datasets (results were analyzed in R after the back-tests were finished with the F4 framework). The red set is where the system was created and the black set is a data-set for the exact same Forex symbol, coming from a completely different source. The correlation between the monthly return of these systems is actually only 0.3, meaning that in practice the classifier used here behaves like two completely different systems across both datasets. When building systems on the daily time frame I never actually faced this issue, because feed differences across daily time frames are not large enough to affect the performance of machine learning systems, while in the lower time frames the differences are magnified (represent a much larger percentage of each bar) so the results are actually very different for machine learning systems trained across two different broker feeds.
–
–
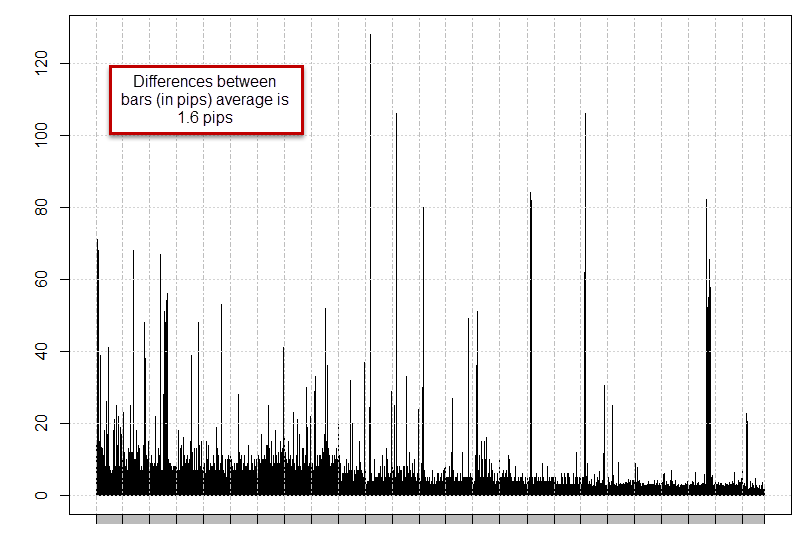
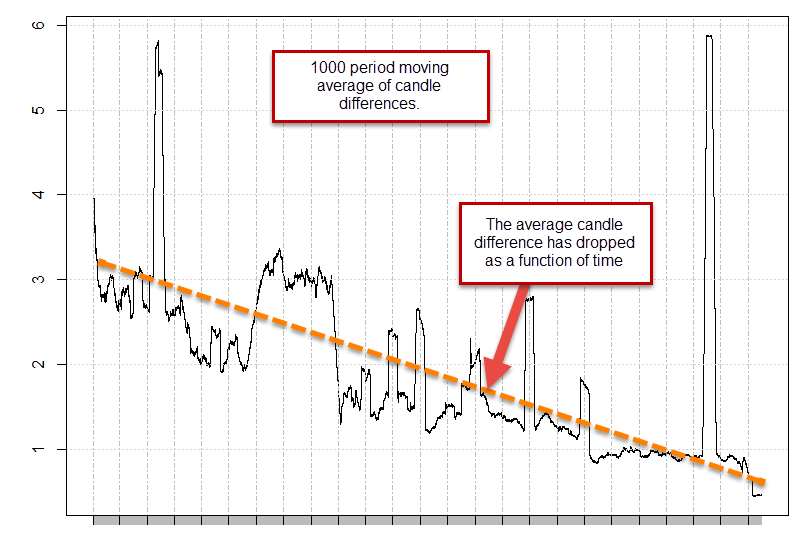
Looking at the difference between both feeds we can actually see two important things. The first is that the difference is most prominent the further we go back in the past and the second is that most differences are actually small (average difference is 1.6 pips). We can also see that the differences in trading system performance are the biggest the further we go back and become much less prominent during the 2008-2012 period. This means that the problem is much less important on recent data and becomes much heavier as the uncertainty surrounding the “fine grain” of the data becomes larger (further disparity between the data sets). Looking at the 1000 moving average of the data feed differences also reveals that differences have been steadily declining as trading has evolved despite the fact that 2008-2009 had a very large volatility peak. If the values were adjusted to volatility the difference would appear even more dramatic. However since broker feed differences are probably affected mainly by liquidity (not simply by market movement ranges) we would simply expect a decline in differences between feeds as the market becomes more liquid (as differences between liquidity providers should smooth).
It is also worth noting that peaks in the feed differences do not seem to affect performance, since these machine learning systems use data from 300-400 learning examples that may very well use the last 10,000 to 15,000 hourly bars. This means that broker differences are only relevant if they are high enough across the whole training sample set (enough to cause wide differences) but are not so important if they only affect a few of these examples. From these graphs we can conclude that the machine learning system – along several others I studied with very similar results – are mainly affected when the average difference for the past 1000 bars is above the 2 pip threshold, as the average has descended below this point, it has become tolerable enough for the systems to give adequate results. So how do we solve this problem? How do we generate results for lower time frame machine learning strategies that work across feeds that were so different historically?
–
–
There are mainly two answers to this question. The first would be to simply ignore previous data and develop systems from 2008 to 2014, since previous data can be considered unreliable regarding the degree of matching needed for machine learning strategies, it would be a good idea to simply consider this data of low quality for machine learning and move on. Surely you may come-up with strategies that have “less powerful” generalizations than if you used 25 years of data but since the data you use is of a better quality (subject to less variability) the models may come up with more useful trading methods.
The second option, is to attempt to build systems that are robust to the perturbations in the past which can – despite of this fact – come up with historically profitable machine learning methods. There are many method that can be used to achieve this purpose but perhaps the most commonly used is to add noise to the data such that any conclusions on either data set will become the same, as the machine learning method would only be left with enough information to see the “very global picture”. If you have an average candle difference of X you can distort all candles by a random quantity 2*X and then you can make a trading decision based on the output of an array of predictors. If you train 200 models with randomly distorted samples and the conclusion is that all of them say that getting into a long trade is the best decision then the answer is probably going to be the same on a different data set where the random distortion is of the same magnitude, if noise doesn’t change the conclusion then the conclusion must be “real” (there must be some underlying quality in the data more important than the added noise). This makes sure that we do not simply find patterns in the inherent noise of the time series but actually find something relevant.
As you can see the problem is quite complex and it will take me a few more blog posts to fully share with you some of my results in the above area. What would you do? Would you trade a machine learning model using data from only the past few years or would you attempt to build a model more robust to broker differences? Let me know in the comments below :o)
If you would like to learn more about machine learning models and how you too can create strategies that retrain daily using our FX trading framework please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





It would make more sense to attempt to build a model more robust to broker differences for two reasons: there are traders from many countries that have biases to their own brokers and face certain restrictions that only allow them to trade with these brokers. Second, do you think history of only three years is sufficient to evaluate the behavior of Mr. Market?
P.S. In reality history will only show, and relentless of these theories, an in depth evaluation by running countless tests will develop appropriate theses. I wish you as always determination and good luck. Thank you again for your hard work.
Hi Chris,
Thanks for posting :o) Those are good points, since you cannot account for the differences between your own broker’s data and the source data, it would make sense to build a model that is robust (regardless of the amount of data used) because the variability between the testing and actual live broker data in the future is unknown. However assuming that broker differences will tend to zero as market liquidity increases (big if?) this might not be such a bad road.
The point you make about length is also interesting. How much data do we need to properly build a machine learning model? Since the model adapts to changes in market conditions (model retrains on every bar) if the retraining process worked across X years can we assume it to be robust? The answer depends on how sensitive the model is to its parametrization (number of examples used for learning, number of inputs used per example, etc). I would say that we cannot know. For some models 2 years of data might be enough, for others 25 years might not be enough. We still lack the experience to tell how sensitive different types of statistical models are to variations on their training parameters.
Thanks again for commenting :o)
Best Regards,
Daniel
I would try to make the model more robust to broker differences by injecting noise into your training samples as described in the linked paper below.
http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=90C06480E22D8E85A911295D1B717228?doi=10.1.1.7.1266&rep=rep1&type=pdf
The reasoning behind this is quite simple – the differences between brokers’ feeds are noise, so recreate this noise in your training set. Take the broker feed you are actually going to use, inject the noise to this and use it as your training set, and keep the “pure” broker feed data as your validation set. Another advantage of this approach is that you will have a theoretically unlimited amount of training data.
Hi Dekalog,
Thanks for posting :o) Yes, this is in fact the solution I mentioned near the end of the post (the paper you posted was one of the ones I read). However there are a few other problems related with the introduction of noise. The question of how much noise to add, how many models to take into account based on noisy data-sets to produce a decision and how to weight their votes all come to mind. I already have some results in this regard which I will share with you guys on a following post. Thanks again for commenting :o)
Best Regards,
Daniel
Discrepancy between brokers, is why 99.99% of Expert Advisers don’t make money. I was comparing monthly charts between brokers, I couldn’t believe the difference, you would think that the monthly charts would look the same, unbelievable! My question is, if an EA is optimized with a broker, then what is the guarantee that the broker’s data feed will remain the same? and why would it change? how would one know in advance?
Regards,
Tony
Hi Tony,
Thanks for posting :o) Before comparing broker feeds you must first ensure that they both have the exact candlestick structure. Make sure you convert both broker’s data to have the same GMT time stamps and DST offsets and also make sure you trim their candles so that they both have the exact same weekly opening/closing times, comparing brokers without first doing this will show you differences that are much larger than expected.
Regarding the future makeup of a broker’s feed, you cannot be sure, this is why you must code your systems to be feed independent. Make sure you always back-test systems across several different long term historical feeds and ensure that differences between results are not important. Also make sure you always carry the above mentioned conversions in live trading to ensure coherence between all feeds used for testing and live trading. Thanks again for writing,
Best Regards,
Daniel
Hi Daniel, first off let me say that I really enjoy reading your blog. You are doing some cutting edge work here.
I would offer the suggestion that you should not rely on broker data for backtesting. Instead I suggest that a more robust approach is to create your own database that you clean yourself.
Also, I would be very leery of any trading system so susceptible to the levels of noise you are talking about. Training with noise is one option, another is just making sure a candidate system passes robustness checks such as adding noise.
But, a fundamental question I have about what you are doing is why purposely put yourself into such a fiercely competitive space attempting to data mine small edges? I’m sure you know that there are very well capitalized hedge funds that do this, so you are effectively entering a compute arms race with them. Do you think you can compete with the likes of Renaissance?
For this reason, I’m kind of surprised you got away from longer term systems.
Hi Dave,
Thanks for writing and for your nice words about my blog :o) Let me now answer your comments,
I do agree with your point on data collection, however since we want to compare system robustness on longer time scales and since we cannot go back to collect data from the past, we do need to get sources of data from third parties. Note that several of these sources are not brokers, some in fact are third parties that do what you say (have collected the data for years).
I would also be very leery of trading anything so susceptible to noise! ;o) This is the reason why these machine learning systems are still on the drawing board. I certainly need them to be much more stable before even contemplating live trading with them. Nonetheless I consider this problem very interesting to share, as it seems to be quite hard to tackle.
Regarding your fundamental question, I believe that we are in fundamentally different spaces. We are not competing with hedge funds like renaissance trying to find edges on the FX 1H timeframes. Funds like these are into much smaller time spaces, finding much smaller price inefficiencies because they have access to high frequency trading (which we do not). Profiting from opportunities in HFT through market making is a far surer thing that attempting to do what we are doing (attempting to find inefficiencies on a higher time frame). This is the information I have received from a few friends in the hedge funds industry.
Regarding time frames, the statistical evidence unequivocally revealed that the 1D time frame is simply worse for trading (more efficient and leads to higher mining bias when building systems) reason why it seemed obvious to move to the 1H, at least on some symbols. That said, I do not consider the 1H “short term” by any means, I think this is till a quite higher time frame (when you think that some people trade on milliseconds). Looking back things have also improved significantly with this decision (from a profit perspective) reason why I don’t regret it one bit :o)
I hope that the above shines some light into what I am thinking :o) If you have any questions don’t hesitate to post again. Thanks a lot again for commenting,
Best Regards,
Daniel