As you may already know, one of my main interests in the development of automated strategies for the Forex market is the development of systems that use machine learning in order to adapt to changes in market conditions. One of the main problems I have when doing this is that – up until now – I have been limited by the amount of data I can use due to the limitations of the MT4 strategy tester and – in general – due to the lack of a wide variety of historical information that I would like to use. Through the following paragraphs we will discuss why this is problematic, what the ideal case would be and the solution I have created – using the F4 framework – in order to ensure that I can run back-tests with as much historical data from as many symbols as I want. Hopefully after finishing this work I will be able to have a virtually unlimited data repository that will enable us – at Asirikuy – to run machine learning tests using relationships between a wide variety of market instruments.
When I first started my journey in machine learning (ML) – with neural network strategies – my first approach was to use data from a given symbol in order to predict its outcome in the future. I was quite successful with this approach on the EUR/USD where I was able to quickly come up with profitable neural network strategies (Sunqu, Paqarin and Tapuy) even being able to create NN strategies that used images in order to learn from the market. However it soon became clear to me that this strategy wasn’t going to be successful on other pairs. Pairs like the USD/JPY and the GBP/USD didn’t seem to be predictable merely from the OHLC information from their own time series. By looking at the academic literature on the matter – although often limited to the accuracy of the ML method and not the actual profit, which is what matters – I was able to conclude that people who made machine learning approaches for these symbols had often used much more complicated ensembles than simple inputs such as the previous day’s bullish/bearish bias.
–
–
My view is that a machine learning method created from an over complicated set of expressions derived from a time series, such as a bunch of different indicators, is much less preferable than a method that is able to predict based on much simpler inputs. My experience tells me that these methods are weak and in fact they have never been able to survive the constant re-training tests to which I submit my ML implementations when back/live trading. Of course, this might be something I’m doing wrong but – in any case – I prefer to focus on methods that use simple inputs to make predictions. So why is it relatively easy to achieve success with a symbol such as the EUR/USD while for the USD/JPY and the GBP/USD it is so difficult? This is a question that I have been asking myself for a while as for me it is fundamental to be able to create ML strategies for as many instruments as I want/need.
My first guess, is that we lack enough information. While the EUR/USD daily rates seem to provide enough information as to make successful predictions about the future, the USD/JPY and the GBP/USD do not contain enough information within their own data to predict their future with a decent accuracy. In this case the PCA analysis reveals that the OHLC variables that lead to higher predictability on the EUR/USD do not work very well on these symbols, pointing to the fact that we are missing the data that explains the variability within these pairs. Obviously it is clear that the movements on a single symbol might be related to a bunch of other symbols and fundamentals that represent wider economic conditions and therefore we might find success in the prediction of these instruments by using data that is not their own OHLC.
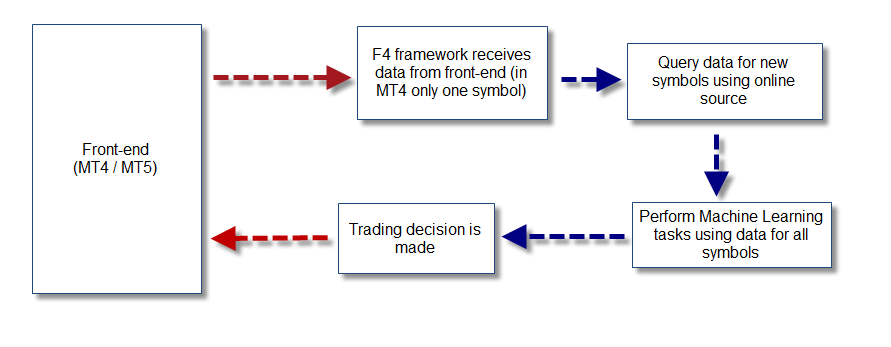
In order to bypass the limitations of the MT4 back-tester, I have decided to create a module for the F4 framework that will be in charge of acquiring historical data from an external source. By using data from an online source I am able to get at least EOD information from a wide variety of symbols up to the point where it is needed. Since obtaining data outside of the back-tester obviously opens up the possibility for data-snooping (as you could get data for future dates relative to your currently back-tested candle) the data is always queried from the online source such that only data up to the last closed date of the back-test is used (therefore avoiding any snooping by design). By implementing this library we are able to get EOD data from any requested symbol (gold, silver, S&P500, Dow, etc) for the date needed within our back-test. When live-trading the library uses the same procedure in order to obtain data up to the last candle close, giving us the possibility to use the exact same mechanism on both live and back-testing.
–
–
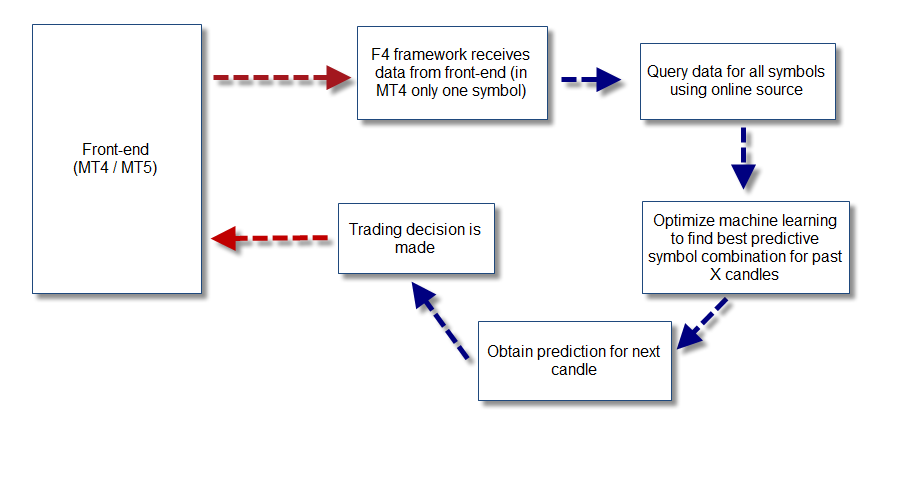
The possibilities that open up are endless. With the ability to query data for a wide variety of instruments we are able to test machine learning approaches that correlate a wide variety of instruments while still using any front-end we want (MT4, MT5, etc). This means that I can now test whether there is a way to predict the USD/CAD using the EOD of oil futures and I can also look at data from the USD index or the EUR index in order to attempt to predict other pairs. The next step is to also include fundamental data – by parsing an online source as well – in order to be able to back-test using correlations between things such as trade balance, interest rate parity, etc. Certainly a true quantitative approach to trading would wrap a whole view of the market, rather than limited predictions based on a single pair’s own EOD data. This module will open up the possibility to get us exactly there, to enable us to make ML based predictions using a really global ensemble of market data. Image a system – as showed above – where the machine learning algorithm is mutated on every bar to actually adapt to the symbols that yielded the most profitable results within the past X bars.
If you would like to learn more about the creation of machine learning strategies and how you too can use the F4 framework to design strategies that use these techniques please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





I completely agree that the use of additional exogenous variables is essential to bolstering predictions garnered from OHLC data. I am working on a similar problem with respect to ML prediction of financial time series, but have come across one snag. All of the data (that which I have found at least) is timestamped with the period for which the data applies, not the date that it was released (when it really impacts the market). For example, the last GDP print is for 4Q 2012, but was released on Feb 28, 2013. It would make the most sense to apply the macro data as of the date it is released instead of the period it is supposed to reflect (since we wouldn’t have known it at the time and therefore cant use it for prediction. Have you considered this issue and if so, what is your approach to addressing it?
Hi Ryan,
Thank you for posting :o) Well I have only looked into using symbol data right now and only relatively simple fundamental data (such as the inter-bank interest rates) so I haven’t ran into the problem you mentioned. However it is clear that you would want to avoid using data that wasn’t available at the time and therefore care should be taken to build a DB that includes these dates or to provide some rules that ensure that you never data snoop. Certainly using data outside of our own tester is a way to invite snooping so due diligence is needed to ensure that this doesn’t happen. I’ll let you know if I run into this problem going forward!
Best Regards,
Daniel
Daniel I thoroughly enjoyed reading this article. I’ve wanted to do these experiments with fundamental data for a long time.
May I suggest that please keep the interface to plug in external data into the F4 framework generic. The interface should allow plugins to be developed that can import data from online, a database etc..
Hi Mun,
Thank you for your comment :o) I am glad you liked the article! Certainly in the beginning I’ll try to make this as generic as possible but the functionality might be simple on the first implementations. Thanks again for posting,
Daniel
Daniel,
I know one person from Linkedin, who uses machine learning to create models for forex, and he only uses OHLC candles. He transforms the data using complex waveforms functions like waveletes as inputs. He maninly uses SOM (Self-organizing_map) to classify groups of candles and get a probability for each group.
He created a model for EURJPY and claims that usd OHLC data (transformed) as inputs.
David
Hi David,
Thank you for your comment :o) I believe it might indeed be possible to use only OHLC data (there are several research papers that show this) but my concern is that the inputs used are generally too obscure (they require complex transformations and classifications as you mentioned). This leads me to believe that you are doing a huge effort to attempt to learn something from the data which might be easier to learn from somewhere else. It might be that what causes the price action in these instruments is a combination of simple correlations with other instruments that get entangled and more difficult to interpret within the actual price action of the symbol you want to predict. Obviously, this is just another path to walk, and using only OHLC is also something I attempt to do :o) Thanks again for posting,
Best Regards,
Daniel
hi Daniel; you indicated that NN strategies are profitable. have you been trading any of these strategies with success?
Hi Scalptastic,
We’ve been trading Sunqu – an NN strategy on the EUR/USD – live for the past several months. Results are profitable and within the expected statistical behaviour up until now. We also have two other strategies Paqarin and Tapuy, which we will probably start trading live before June. Tapuy uses image recognition for trading. I hope this answers your question,
Best Regards,
Daniel
Hi Daniel,
for your Front end platform framework is it currently compatible to use multicharts and jForex? because i have been not using metatrader for so long to trade forex. my current broker is LMAX exchange and dukascopy.
And with the framework is it possible to code it and become dll to build indicator in Multicharts or any platform. For example to generate trained or unsupervised DLL for NN & GA then build indicator in other platforms?
Thanks.
Hi Eto,
Thank you for your post :o) We are working on a JForex front-end but we do not have plans for a MultiCharts front-end yet. The framework is executed through a DLL so certainly any indicators using NN or GA libraries can be coded within it if a front-end is available for the platform used. I hope this clears up any doubts!
Best Regards,
Daniel
Hi Daniel,
Loved the article, I am building something similar through FXCM’s Java API as an external source of price information. I am only working with forex rates but would like to expand out to other symbols soon. I was wondering if you had any experience working with the FIX Protocol and whether you think it would be worth going through the entire implementation process.
Enjoy the blog and keep the posts coming.
Best,
Tad