Building trading systems that rely on machine learning is an often difficult task that relies on a wide array of different expertise. These include the user’s ability to analyze data, determine adequate input/output structures and come up with adequate training/testing regimes to eliminate or at least attenuate the different types of bias that surface through the model building process. To start a journey towards the creation of a machine learning system it is often better to start with simple modeling schemes that can still be used for things like manual market predictions and can later be automated for the creation of algorithmic systems. Today we are going to learn how to create a simple machine learning model in R to help us predict the daily return of a dollar index ETF (the UUP). My objective with this post is to share with you how this can be done in practice, although it is up to you (with the basis I am giving you here) to improve the model such that you can arrive to more useful results. After reading this article you’ll be able to build a machine learning model in R and you will also have an idea of how difficult it can be to come up with results that give useful outputs. Before going through this article please make sure you have R installed as well as the quantmod, caret, ggplot2, e1071 and rpart libraries. Using R Desktop is also highly recommended.
–
library(caret)
library(ggplot2)
library(e1071)
library(rpart)
getSymbols("UUP",src="google")
daily <- dailyReturn(UUP)
daily <- na.omit(daily)
–
Today we are going to build a support vector machine (SVM) regression model using the daily returns of the UUP ETF in order to attempt to predict its next daily return value. An SVM is a very useful machine learning model, since it is especially well equipped to deal with high dimensionality problems and allows us to easily tune parameters that allow us to control generalization from examples and how astringent training can be. We are going to use quantmod to get data, we are then going to process the data to generate an adequate input/ouput structure, we are then going to split this data into training and validation sets and finally we are going to go through the machine learning model generation process, generating graphs that will allow us to see how well our model is able to predict the daily returns on the UUP ETF. First of all make sure that you adequately load all needed libraries and generate the daily return series of the UUP ETF (above). Note that we create the daily returns using the dailyReturn function from quantMod and we then use the na.omit function to ensure that we don’t have any lines with NA data in our object.
Once we do this we can now start to process the data. In this case we’re going to use information from the past 9 days in order to predict the return of the current bar. This means that we need to create a new data frame where the first column represents the return we want to predict (the output) and the next 9 columns represent the past 9 days relative to each output (the inputs for each output). The total length of the data-frame object (number of columns) is defined by the variable “t”. We will be creating a data-frame named data, assign it a number of rows equal to “k” and a number of columns equal to “t”, we will give each column an appropriate name (first is “ouput”, then they will be called “inputX”) and then we’re going to go through a loop that will populate rows for each column per what was mentioned before. The correct construction of this loop is of the utmost importance as errors in indexes will lead to data-snooping bias, meaning that the desired prediction – or some other information about the future – is included within the inputs by mistake (always suspect this if your results seem “too good to be true”).
–
t <- 10
k <- length(daily[,1])-t+1
data <- data.frame(matrix(NA, nrow = k, ncol = t))
colnames(data)[1] <- "output"
for (i in 2:t){
colnames(data)[i] <- paste(c("input", i), collapse = "")
}
j=1
for (i in t:length(daily[,1])){
data$output[j] <- daily[i, 1]
for(n in 2:t){
data[j,n] <- daily[i-n+1, 1]
}
j = j+1
}
–
Now that we have built the proper dataframe to feed to the machine learning model we need to split our data into training/testing sets in order to train and then validate our model. In order to do this we will use the caret package to split our set into a training set (70% of the data) and a testing set (30% of the data). The data is split randomly to yield an equal – or at least as equal as possible – distribution of the ouput variable across both sets. We then train our machine learning model (called “r1”) using the svm function. Note that the SVM function has two parameters (C and gamma) which are both critical for the construction of the model. The C parameter has to do with how much training you want to do (how tightly you want to fit the training data) while the gamma parameter has to do with the contribution of each example to the general model (something alike how much the information between examples is “mixed” to generate the model — excuses for the gross oversimplification to my canonical readers). Using a smaller C value means that your model will be less fitted to the training data while using a low gamma will mean that the overall model will be more specific and less generalized. Usually a lower gamma implies that you’ll need a higher C to achieve the same amount of error in the training set and vice versa. Make gamma too high and your model will completely fail to classify in training. Play with C and gamma and see what you get :o)
–
trainIndex <- createDataPartition(data$output, p = 0.70, list = FALSE, times = 1) efTrain <- data[trainIndex, ] efTest <- data[-trainIndex, ] r1 <- svm(output ~ ., data = efTrain, cost = 1000, gamma = 0.01)
–
After this is done we can now generate graphs with the testing/training sets in order to see how well our model was able to predict the training set and how well it is able to perform on data that is outside of its own training (note that your results might differ in some aspects as the split of the train/test set is random every time). We can generate a very nice graph using ggplot2 in order to carry out this analysis. In this case we’re going to draw our training set in blue and our testing set in red. It is no mystery that the results of the model are quite disastrous, especially for values of the daily return that are at least 1 standard deviation away from the mean of returns. As a matter of fact our model completely breaks down when we would like it to work the most (when days that would offer large movements appear). The testing error (also calculated below) shows that on average we make a mistake of +/- 0.7%, this means that we’re just practically guessing when making predictions on testing data.
–
p <-ggplot()
p <- p + geom_point(size=3, aes(x=efTrain$output ,
y=predict(r1, efTrain), colour="Training set"))
p <- p + geom_point(size=3, aes(x=efTest$output ,
y=predict(r1, efTest), colour="Testing set"))
p <- p + ylab("Predicted return")
p <- p + xlab("Real return")
p <- p + theme(axis.title.y = element_text(size = rel(1.5)))
p <- p + theme(axis.title.x = element_text(size = rel(1.5)))
p <- p + theme(axis.text.x = element_text(angle = 45, hjust = 1))
p <- p + theme(panel.background = element_rect(colour = "black"))
p
efTest$error <- 100*(abs(predict(r1, efTest)-efTest$output))
efTest <- na.omit(efTest)
mean(efTest$error)
–
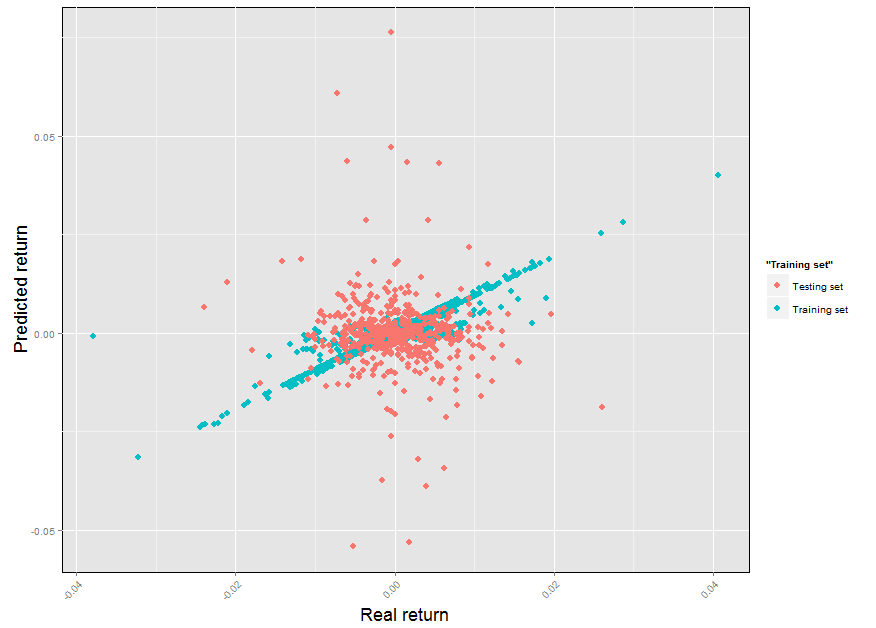
–
The above already shows you a few of the big problems that are encountered when attempting to use machine learning to predict the daily return of financial time series. The cases that we want to have the most accuracy in predicting are the cases that are most difficult to predict, both because we have too few examples and because those examples where movements are less significant are simply much more abundant than those where movements are larger. It also happens that the most common outcome is to have a small increase/decrease close to zero and this “noise” is very problematic when attempting to generate a statistical model for the financial time series. The above inputs are also among the simplest predictors you can choose, there are certainly better choices to be made. All the above problems are difficult but certainly not insurmountable, there are a variety of tactics that can be employed to arrive at better statistical models for the prediction of daily returns in financial time series. Hopefully the above will give you a lot to play with in R to build your own machine learning models :o)
If you would like to learn more about machine learning and how you too can build systems that retrain their models every day and achieve profitable historical results on Forex data please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





very usfull article! thanks for the detailed explantions and examples