Building machine learning strategies that can obtain decent results under live market conditions has always been an important challenge in algorithmic trading. Despite the great amount of interest and the incredible potential rewards, there are still no academic publications that are able to show good machine learning models that can successfully tackle the trading problem in the real market (to the best of my knowledge, post a comment if you have one and I’ll be more than happy to read it). Although many papers published do seem to show promising results, it is often the case that these papers fall into a variety of different statistical bias problems that make the real market success of their machine learning strategies highly improbable. On today’s post I am going to talk about the problems that I see in academic research related with machine learning in Forex and how I believe this research could be improved to yield much more useful information for both the academic and trading communities.
–
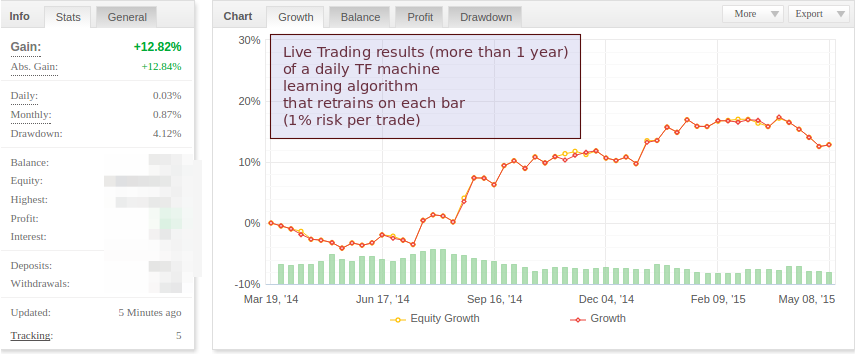
–
Most pitfalls in machine learning strategy design when doing Forex trading are inevitably inherited from the world of deterministic learning problems. When building a machine learning algorithm for something like face recognition or letter recognition there is a well defined problem that does not change, which is generally tackled by building a machine learning model on a subset of the data (a training set) and then testing if the model was able to correctly solve the problem by using the reminder of the data (a testing set). This is why you have some famous and well established data-sets that can be used to establish the quality of newly developed machine learning techniques. The key point here however, is that the problems initially tackled by machine learning were mostly deterministic and time independent.
When moving into trading, applying this same philosophy yields many problems related with both the partially non-deterministic character of the market and its time dependence. The mere act of attempting to select training and testing sets introduces a significant amount of bias (a data selection bias) that creates a problem. If the selection is repeated to improve results in the testing set – which you must assume happens in at least some cases – then the problem also adds a great amount of data-mining bias. The whole issue of doing a single training/validation exercise also generates a problem pertaining to how this algorithm is to be applied when live trading. By definition the live trading will be different since the selection of training/testing sets needs to be reapplied to different data (as now the testing set is truly unknown data). The bias inherent in the initial in-sample/out-of-sample period selection and the lack of any tested rules for trading under unknown data makes such techniques to commonly fail in live trading. If an algorithm is trained with 2000-2012 data and was cross validated with 2012-2015 data there is no reason to believe that the same success will happen if trained in 2003-2015 data and then live traded from 2015 to 2017, the data sets are very different in nature.
–

–
Measuring algorithm success is also a very relevant problem here. Inevitably the machine learning algorithms used for trading should be measured in merit by their ability to generate positive returns but some literature measures the merit of new algorithmic techniques by attempting to benchmark their ability to get correct predictions. Correct predictions do not necessarily equal profitable trading as you can easily see when building binary classifiers. If you attempt to predict the next candle’s direction you can still make a loss if you are mostly right on small candles and wrong on larger candles. As a matter of fact most of this type of classifiers – most of those that don’t work – end up predicting directionality with an above 50% accuracy, yet not above the level needed to surpass commissions that would permit profitable binary options trading.
To build strategies that are mostly rid of the above problems I have always advocated for a methodology in which the machine learning algorithm is retrained before the making of any training decision. By using a moving window for training and never making more than one decision without retraining the entire algorithm we can get rid of the selection bias that is inherent in choosing a single in-sample/out-of-sample set. In this manner the whole test is a series of training/validation exercises which end up ensuring that the machine learning algorithm works even under tremendously different training data sets. I also advocate for the measuring of actual backtesting performance to measure a machine learning algorithm’s merit and furthermore I would go as far as to say that no algorithm can be worth its salt without being proven under real out-of-sample conditions. Developing algorithms in this manner is much harder and I haven’t found a single academic paper that follows this type of approach (if I missed it feel free to post a link so that I can include a comment!).
This does not mean that this methodology is completely problem free however, it is still subject to the classical problems relevant to all strategy building exercises, including curve-fitting bias and data-mining bias. This is why it is also important to use a large amount of data (I use 25+ years to test systems, always retraining after each machine learning derived decision) and to perform adequate data-mining bias evaluation tests to determine the confidence with which we can say that the results do not come from random chance. My friend AlgoTraderJo – who also happens to be a member of my trading community – is currently growing a thread at ForexFactory following this same type of philosophy for machine learning development, as we work on some new machine learning algorithms for my trading community. You can refer to his thread or past posts on my blog for several examples of machine learning algorithms developed in this manner.
If you would like to learn more about our developments in machine learning and how you too can also develop your own machine learning strategies using the F4 framework please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.





Great article, the problems you highlight are certainly valid for system robustness!
A question I have, is it normal for say an EA to do exceedingly well in a certain pair and do terrible in all others?
Or, should a robust EA do well in at least several pairs, without any change in settings!
Thanks, for your great thoughts.
That question is interesting ;o). I believe that the question is better phrased as “can a system that survives on only one pair generate returns when live traded?” the answer is yes (both from theory and from my own experience). Having returns on only one pair does not mean that the system is “bad” it simply means that it exploits a historical inefficiency that is only present on one instrument. Provided you take care of bias sources (such as data-mining bias and curve-fitting bias) there is no reason why this will not work.
Now, if you have a system that works across many symbols then data-mining bias will be exponentially lower for an equal system that only works on one symbol and curve-fitting bias will also be lower due to the use of more data. So I would say that it’s better, but definitely not required.
But remember, measure your statistical biases!
I am so glad that you said it does not have to make a profit across all pairs! Also curve fitting, how does one know the limit of tweaking allowed before it becomes fitted?
Finally, I did a very simple test using the bog standard Moving Average EA on MT4, to see which pairs would react most widely to MAs. I backtested 52 pairs to see how many ‘Moving Period’between (1-20) would make a profit, regardless of drawdown. I wondered what you make of the results!
* 5 year test period.
* H4 TF.
* Drawdown not measured.
* 52 Pairs tested.
* Settings tested (Periods 1-20).
1 23 pairs, made no profit on any bar settings 1-20.
2 6 pairs, could only make profit on 1 setting.
3 14 pairs only, returned a profit on 5, or more different settings.
4 5 pairs only, returned a profit on 10, or more different settings.
TOP 5
1 BTCUSD 19 Settings out of 20, made a profit.
2 XAUUSD 17
3 EURNZD 16
4 EURJPY 15
5 GBPNDU 10
You need to make a distinction between curve-fitting bias and data-mining bias (or at least these two different types of bias, however you may want to call them). Curve-fitting bias is a bias created by finding an inefficiency across a set of data, it answers the question: is my system finding something general or something specific to the data I am using?. Data-mining bias answers the question: is my system finding a real historical inefficiency or are the results just because of my mining process (meaning coming from random chance)?
By increasing parameter spaces and degrees of freedom you are increasing data-mining bias (you are more likely to find a system just by chance, instead of a system that trades a real historical inefficiency). You can measure data-mining bias by using a test like White’s reality check. Doing this type of test is fundamental to reliable strategy design.
Read more about this distinction between biases here:
http://mechanicalforex.com/2014/12/two-statistical-bias-types-understanding-sources-of-bias-when-building-trading-strategies.html
Also read this paper on the subject:
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2308659
Before dwelling into the complexities of trading system design and finding strategies for trading I strongly advice getting a solid formation in statistics (coursera statistics courses are an excellent free start). Statistics will give you the power to analyse your own results and methodically address questions like these ;o)
[…] Machine Learning in Forex Trading: Why many academics are doing it all wrong [Mechanical Forex] Building machine learning strategies that can obtain decent results under live market conditions has always been an important challenge in algorithmic trading. Despite the great amount of interest and the incredible potential rewards, there are still no academic publications that are able to show good machine learning models that can successfully tackle the trading problem in the real m […]