The creation of machine learning systems can be very challenging due to the potential complexity of the resulting systems and the high level of statistical biases that can be present when using methods that have an inherently powerful ability to learn from the underlying data. We have decided to undertake this challenge at Asirikuy using very simple machine learning systems for which highly stable systems can be found on very long term back-tests (28 years) on a significant number of different Forex trading symbols. On today’s post I want to share with you some of our initial results as well as how we have performed our data-mining bias evaluation process to have a high confidence that these systems come from the exploitation of real historical inefficiencies and not simply from random chance due to the strength of the mining process.
–
–
The machine learning systems we have decided to search for are systems that use simple linear regression algorithms and input/output structures to learn from the market. Inputs are generally past bar returns while outputs are related directly with trade outcomes. The systems have function based trailing stop mechanisms and have no take profit parameters. As in the case of all our previous machine learning algos the retraining of the machine learning algo is performed on every bar using a given number of past examples. If you want to learn more about this type of machine learning algorithm I recommend AlgoTraderJo’s thread at Forex Factory, where he takes the time to thoroughly explain how the above systems work and how they are actually built. However I would also like to point out that the exact input/output/trailing stop structure I am describing here is not present within his thread but just the general idea of how this type of algorithms work and many examples based on other input/output structures (many from his own research).
–

–
When creating these machine learning algorithms we face a significant number of parameters that shape the actual system that will be traded. The number of examples used to retrain on each bar, the number of inputs for each example, the size of the stop loss, the characteristics of the trailing stop, etc. In order to properly assess whether systems resulting from searching this parameter space contain a high level of data mining bias it becomes critical to perform a proper data mining bias (DMB) assessment as I have described previously. As with other types of mining we perform the exact same search process across random data sets generated using bootstrapping with replacement from the original time series. In this we initially chose a search space consisting of around 12600 systems which was tested across 5 different Forex symbols to see the level of DMB. Only strategies that had a log(balance) Vs time linear correlation coefficient above 0.90 were considered as potential candidates for addition.
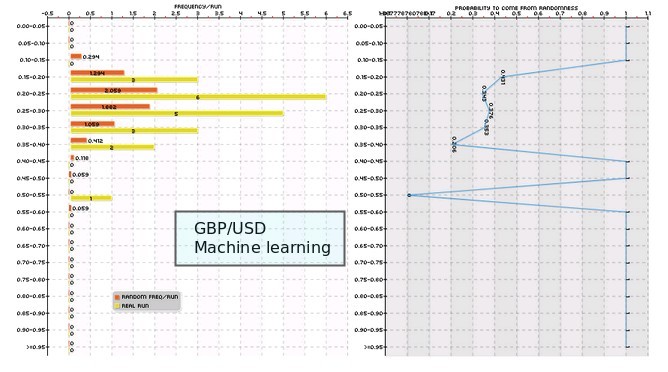
The above process revealed that for some symbols – under the space explored – the amount of mining bias is very large and therefore no systems can be considered for actual trading since they cannot be distinguished from systems generated by random chance within the mining process. A good examples is the GBP/USD – showed above – where the mining bias is very large for all the CAGR/MaxDrawdown classes and therefore we can consider that the machine learning searching process had a high chance of generating a system that was simply the consequence of the strength of the mining process. The same happens in the case of GBP/JPY while for the EUR/USD and USD/JPY we could find systems that had a low DMB (probability to not come from historical inefficiencies lower than 1%). This means that we could use these systems to construct a machine learning algo repository that we can use for actual trading.
–
–
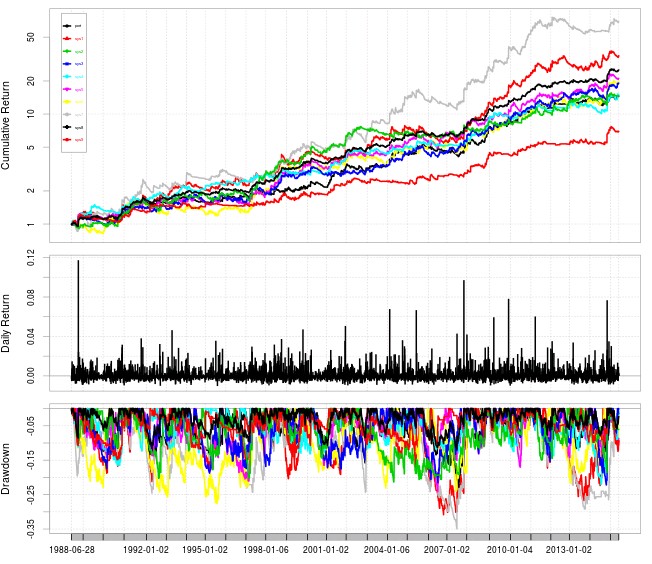
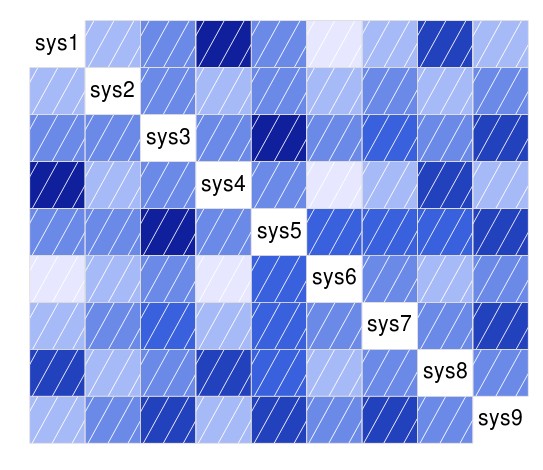
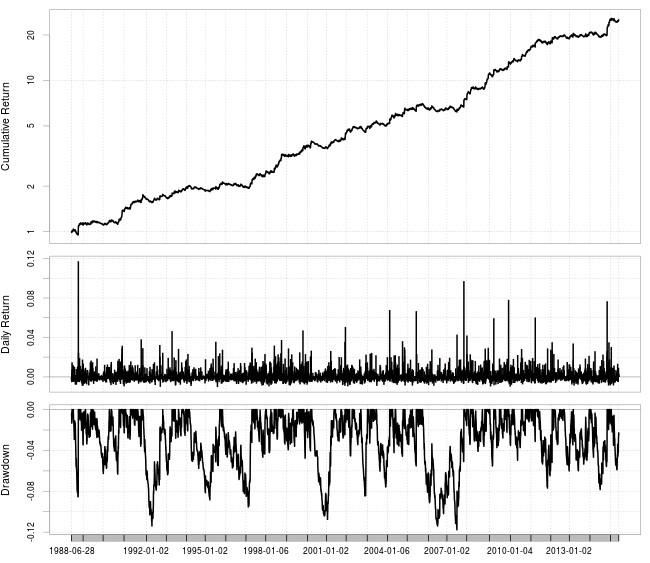
In the case of the USD/JPY I took all systems belonging to classes with a mining bias below 1% and recreated their back-testing results. The systems are all highly stable strategies and therefore are able to generate highly linear charts in a log(balance) Vs Time graph. As you can see on the image depicting the 9 systems trading is substantially different for most of them and correlations are actually only strong between a few systems (see correlation heat map, blue means higher correlation of returns). This means that we can trade only 6 of them if we want all inter-system correlations to have an R2 of 0.5 or lower. We can also build an equally weight portfolio for all these systems (giving all systems a risk of 0.11% per trade for a total risk around 1%). In this manner we generate the portfolio curve shown (last image on this post) that depicts the power of combining systems that have overall small correlations between them.
These systems – which I will be releasing in Asirikuy tomorrow – are the first fruita of our cloud mining machine learning system searching venture (where many Asirikuy members contribute mining power to make DMB evaluations and find profitable ML systems). They also represent our first finding of low DMB machine learning systems and the first contributions to our machine learning systems repository. I would also like to be clear in that right now we have no idea whether these trading systems will generate positive performance under real live trading conditions. Our experience points to this being a very probable case but we definitely will need to test this live.
–
–
Mining of machine learning systems will also continue at Asirikuy, building a machine learning portfolio that will be complimentary to our current pKantu price action based system repository (which already has more than 300 trading strategies). If you would like to learn about Asirikuy and our current system mining abilities please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.




