On a recent post I talked about how you can evaluate some aspects of your Forex data quality by using a python script. Through this article I showed you a python script to search for holes within your Forex historical data and make an assessment regarding data quality based on this number. However there are other aspects to data quality besides simply missing data and today we are going to dedicate an article to a more elaborate python script to evaluate Forex historical data quality. Through this article I will introduce several additional notions relevant to Forex data quality and will share a python script that will help you evaluate the quality of historical data in MT4 data format (so you can evaluate the quality of data exported from your MT4 platform’s history center or any other data in this format).
–
#!/usr/bin/python
# MT4 format data quality evaluation script
# By Daniel Fernandez, 2015
# Mechanicalforex.com
# Asirikuy.com
import subprocess, os, csv
from time import *
from math import *
import pandas as pd
import numpy as np
import sys
import fileinput
from datetime import datetime
from datetime import timedelta
import matplotlib.pyplot as plt
import argparse
ohlc_dict = {
'open':'first',
'high':'max',
'low':'min',
'close': 'last',
'vol': 'sum'
}
def findDuplicates(historyFilePath):
duplicates = []
with open(historyFilePath, 'rb') as f:
reader = csv.reader(f)
for index,row in enumerate(reader):
if index > 0:
if lastRow == row[0]+row[1]:
duplicates.append(row)
lastRow = row[0]+row[1]
return duplicates
def parse_datetime(dt_array, cache=None):
if cache is None:
cache = {}
date_time = np.empty(dt_array.shape[0], dtype=object)
for i, (d_str, t_str) in enumerate(dt_array):
try:
year, month, day = cache[d_str]
except KeyError:
year, month, day = [int(item) for item in d_str[:10].split('.')]
cache[d_str] = year, month, day
try:
hour, minute = cache[t_str]
except KeyError:
hour, minute = [int(item) for item in t_str.split(':')]
cache[t_str] = hour, minute
date_time[i] = datetime(year, month, day, hour, minute)
return pd.to_datetime(date_time)
def monthlyDistribution(df):
fig, ax = plt.subplots(figsize=(10,7), dpi=100)
n, bins, patches = ax.hist(df['month'], 12,facecolor='green', alpha=0.75, align='left')
plt.xlabel('Month')
plt.ylabel('Frequency')
plt.title('Missing data distribution by month')
plt.grid(True)
labels_x = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
ax.set_xticklabels(labels_x, minor=False)
ax.set_xticks(bins[:-1])
plt.xticks(rotation=90)
plt.show()
def yearlyDistribution(df):
fig, ax = plt.subplots(figsize=(10,7), dpi=100)
n, bins, patches = ax.hist(df['year'], len(set(df['year'])), facecolor='green', alpha=0.75, align='left')
plt.xlabel('Year')
plt.ylabel('Frequency')
plt.title('Missing data distribution by year')
plt.grid(True)
labels_x = list(set(df['year']))
ax.set_xticklabels(labels_x, minor=False)
ax.set_xticks(bins[:-1])
plt.xticks(rotation=90)
plt.show()
def dayofweekDistribution(df):
fig, ax = plt.subplots(figsize=(10,7), dpi=100)
n, bins, patches = ax.hist(df['dayofweek'], len(set(df['dayofweek'])), facecolor='green', alpha=0.75, align='left')
plt.xlabel('Day of week')
plt.ylabel('Frequency')
plt.title('Missing data distribution by day of week')
plt.grid(True)
labels_x = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
ax.set_xticklabels(labels_x, minor=False)
ax.set_xticks(bins[:-1])
plt.xticks(rotation=90)
plt.show()
def dayDistribution(df):
fig, ax = plt.subplots(figsize=(10,7), dpi=100)
n, bins, patches = ax.hist(df['day'], len(set(df['day'])), facecolor='green', alpha=0.75, align='left')
plt.xlabel('Day of month')
plt.ylabel('Frequency')
plt.title('Missing data distribution by day of month')
plt.grid(True)
labels_x = list(set(df['day']))
ax.set_xticklabels(labels_x, minor=False)
ax.set_xticks(bins[:-1])
plt.xticks(rotation=90)
plt.show()
def hourlyDistribution(df):
fig, ax = plt.subplots(figsize=(10,7), dpi=100)
n, bins, patches = ax.hist(df['hour'], len(set(df['hour'])), facecolor='green', alpha=0.75, align='left')
plt.xlabel('Hour')
plt.ylabel('Frequency')
plt.title('Missing data distribution by hour')
plt.grid(True)
labels_x = list(set(df['hour']))
ax.set_xticklabels(labels_x, minor=False)
ax.set_xticks(bins[:-1])
plt.xticks(rotation=90)
plt.show()
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-f', '--filename')
parser.add_argument('-tf', '--timeframe')
args = parser.parse_args()
filename = args.filename
timeframe = args.timeframe
if filename == None:
print "Filename missing (-f)."
sys.exit()
if timeframe == None:
print "timeframe missing (-tf)"
sys.exit()
historyFilePath = filename
timeframe = timeframe
if "JPY" in historyFilePath:
roundFactor = 3
else:
roundFactor = 5
df = pd.read_csv(historyFilePath, header=None)
df.columns = ['date', 'time', 'open', 'high', 'low', 'close', 'vol']
df = df.set_index(parse_datetime(df.loc[:, ['date', 'time']].values, cache={}))
df = df.drop('date', 1)
df = df.drop('time', 1)
df = df.round(roundFactor)
df2 = df
selector_bad_data = ((df2['high']<df2['low']) | (df2['high']<df2['open']) | (df2['high']<df2['close']) | (df2['low']>df2['open']) | (df2['low']>df2['close']) | (df2['vol'] < 0))
bad_ohlcv = df2[selector_bad_data]
df2 = []
df2 = df
df2['change'] = abs(df2['open'].pct_change())
df2['delta'] = df2.index
df2['delta'] = (( df2['delta'].shift(0)-df2['delta'].shift(1))/ np.timedelta64(1, 's')).dropna().astype(int)
spikes = df2[(df2['change'] > 0.01) & (df2['delta'] < 3600)]
df2 = []
df = df.resample(timeframe, how=ohlc_dict, base=0)
df = df.reindex(columns=['open','high','low','close', "vol"])
hour = df.index.hour
dayofweek = df.index.dayofweek
selector = ((0<dayofweek) & (dayofweek<4))
df = df[selector]
day = df.index.day
month = df.index.month
selector = (((day != 24) & (day != 25) & (day != 26) & (day != 31) & (month==12)) | ((day > 2) & (month==1)) | ((month > 1) & (month < 12)))
df = df[selector]
duplicates = findDuplicates(historyFilePath)
missing_data = df[df.isnull().any(axis=1)]
missing_data_count = len(missing_data)
missing_data['year'] = missing_data.index.year
missing_data['month'] = missing_data.index.month
missing_data['hour'] = missing_data.index.hour
missing_data['day'] = missing_data.index.day
missing_data['dayofweek'] = missing_data.index.dayofweek
monthlyDistribution(missing_data)
yearlyDistribution(missing_data)
hourlyDistribution(missing_data)
dayDistribution(missing_data)
dayofweekDistribution(missing_data)
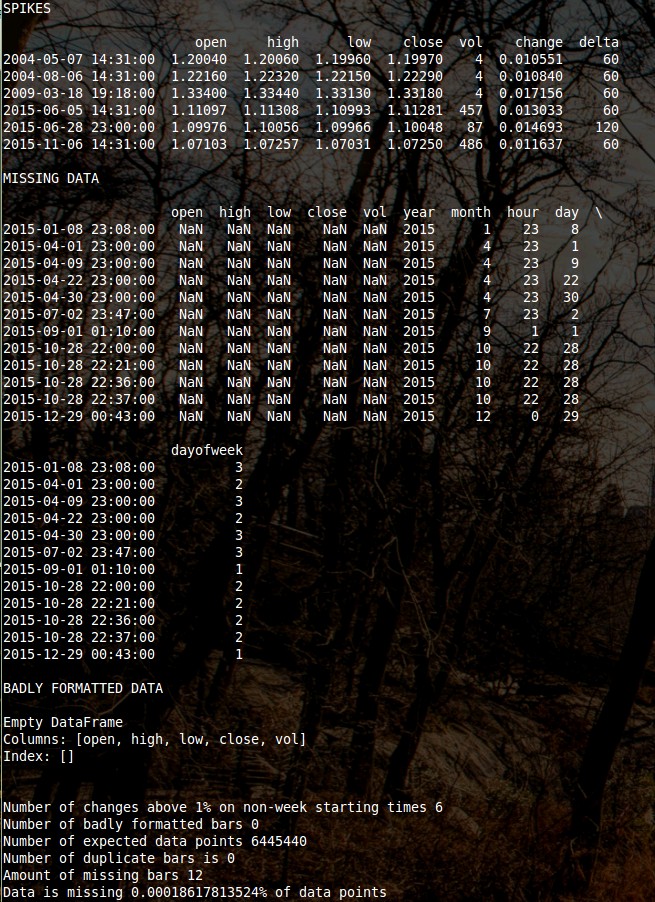
print ""
print "SPIKES"
print ""
print spikes
print ""
print "MISSING DATA"
print ""
print missing_data
print ""
print "BADLY FORMATTED DATA"
print ""
print bad_ohlcv
print " "
print " "
print "Number of changes above 1% on non-week starting times {}".format(len(spikes))
print "Number of badly formatted bars {}".format(len(bad_ohlcv))
print "Number of expected data points {}".format(len(df))
print "Number of duplicate bars is {}".format(len(duplicates))
print "Amount of missing bars {}".format(missing_data_count)
print "Data is missing {}% of data points".format(100*float(missing_data_count)/float(len(df)))
print " "
print " "
##################################
### MAIN ####
##################################
if __name__ == "__main__": main()
–
Yes, there is a lot more to Forex data quality than simply missing data. Although having periods missing is a main problem with bad quality data there are other issues besides holes that might be even worse when using a historical data set. There are 5 other issues that are extremely important to evaluate in order to ensure that one has a high quality data set, 4 of which we will be tackling through the use of the above python script. As in the previous script I shared this script needs to be called using two arguments, the first being the file to be examined (-f) and the second the timeframe (-tf) of this file in pandas format. This means that to evaluate a 1 minute file you would you “-tf 1T” since T is the 1 minute identifier for the pandas resampling function (you can also use 1H for hourly data or 1D for daily data). This new script uses a highly efficient function to load the MT4 formatted data so it can load a 28 year 1M data set in under a minute on a 4770 i7 processor (provided you have enough RAM and a python 64-bit installation).
The script’s tests for data quality attempt to ensure that the data is both complete and coherent. Completeness is evaluated by looking at holes present within the data while coherence depends on a number of different factors. The first thing that the script evaluates is whether there are any bars within your data that are inconsistent, meaning that they violate any of the basic characteristics that the information contained within the bars must fulfill. For example we expect that for every bar the High should be higher than the low, open and close values while the low should be lower than the high and lower than the open and close as well. Any violation of these constraints supposes a problem with the data as it implies that the bar has been generated erroneously. The script searches for bars that violate these rules and prints the number of bars that do so.
–
–
After doing this the script then searches for spikes (changes above 1% between different bar opens within the data) outside of week-ends, this is a hint that something might be going on. If you have a jump above 1% outside of a week-end gap then this means that you might have a rogue bar or a sudden change within the data that might imply some wrong aggregation or processing of the data series. Sometimes this might be normal – it can happen a few times within a very long period – but in general you will want to examine each one of these occurrences through a magnifying glass to ensure that they are all normal and not a symptom of wrongly processed data. A clear tell-tale sign of this being due to bad data quality are closely occurring spikes of X% which imply a rogue abandoned single or set of candles that might have been wrongly processed.
Besides searching for spikes and adequate fulfillment of OHLC constraints within the data the script also looks for duplicate bars, another symptom that something might be wrong. There must be a single unique timestamp for each bar within the data and having two bars with the same time-stamp is a definite symptom that something is very wrong. This might happen because a provider badly merging the data, possibly due to millisecond differences in timestamps that are eliminated when the 1M bars are generated. There can also be other reasons why this happens but it is always a sign that something is wrong within the historical data. A clean data set must contain zero duplicate bars.
–

–
The last important point to data quality – which the script does not cover – is the consistency of the GMT shifts and DST offsets within the data. I wrote a post about this last month which shows you how you can determine the GMT shifts and whether your data has or hasn’t got DST using the NFP news release. Sadly the NFP is not a tremendously consistent behavior – because clearly there is no rule that the NFP bar must be the largest bar within that day – but it provides a good guide of whether they might be something wrong within your data. If you use that script and perform the test for all DST and non-DST months across all years within your data you might be able to make a much better assessment of whether this is or is not the case. Note that this is one of the biggest problems with data from FX brokers, some brokers like Alpari used a GMT offset up until some point, time after which they changed it abruptly to another value (without correcting the previous historical data). Using data that is – for example – GMT +1/+2 on some years and then GMT +2/+3 on others assuming that the GMT shift and DST is constant through the data can be a fatal mistake with very big costs in terms of real money.
Although controling data quality can often be a laborious task it is of absolute importance if you want to ensure that your back-testing results are reliable. Having data for which you do not know the GMT/DST, data that is filled with holes, that violates OHLC constraints or that has duplicate bars can heavily jeopardize your efforts in the development of Forex trading strategies. There are many traders who have lost money simply because they performed their system creation processes on bad data, either because they didn’t know or neglected to perform adequate data quality testing. If you want to learn more about backtesting or data refactoring or if you want to get access to a high quality long term 1M data set for many FX symbols please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.




