During the past year we have been making a significant effort at Asirikuy in the building of machine learning portfolios. Although we have faced several setbacks along this time – which has meant we have had to restart our process a couple of times – we now have a solid idea of how to build the portfolio and create an ML based repository. One critical aspect of this entire exercise is of course performance, since we require to have system executions that are as fast as possible if we are to perform the expensive tasks that are data mining bias assessment and strategy mining. On today’s post I want to share with you my performance analysis of our F4 machine learning trading strategies so that you can get an idea of how different parts of the system back-testing take and what I have done to improve this testing time significantly.
–
–
For starters it’s important to understand the different parts of the back-testing process. In our F4 framework and back-testing software the first thing we do is load historical data and general configuration information into memory using python, this data is then passed to a C coded tester that then performs the back-testing process by executing the strategy over all the data points provided, performing an event-based back-testing exercise. Within each back-testing cycle the tester calls the F4 framework which then executes the trading strategy and returns a series of instructions telling the tester what it wants to do (open, close, modify positions, etc). In the end some statistics are calculated and the data is returned to python which then performs some final cleanup and result file generation – if requested – and then finishes the execution of the program. All the hard work is done under a very efficient C/C++ environment while configuration file loading, result file generation and things of this sort are left to the python front-end.
Most of the performance cost in back-testing is spent executing the F4 framework – where the strategy resides – especially if you’re back-testing a machine learning program. In the execution of our machine learning strategies the program usually does three things. The strategy first creates a moving window of training examples by going through historical data. This window is generally an array containing input and output vectors which are constructed in different manners depending on what the user specifies. The strategy then uses this input/output vectors to train a machine learning algorithm which is usually something like a linear regression or a neural network. After training the algorithm the strategy then draws a prediction based on the last set of inputs and makes a trading decision based on what that prediction is.
–

–
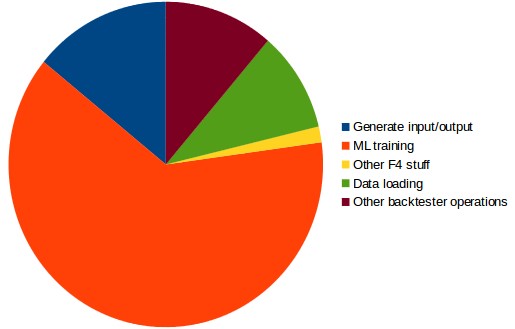
In general a back-test spends around 78% of the time executing F4, around 12% executing back-tester related operations – such as shifting the data to pass to the F4 framework and calculating statistics – while 10% is spent doing things like initial data loading. In the time spent running the F4 framework generally 17% of the time is spent doing input/example generation, 80% of the time is spent doing the actual machine learning algorithm training and around 2% of the time is spent doing other stuff like refactoring rates, making trading decisions or making lot sizing calculations. As you can see the highest cost is paid in the machine learning training which costs around 80% of the F4 execution time and therefore around 62% of the entire overall execution time.
It is evident from the above that the best way to improve execution is to reduce the ML training time. Many of you may think that the easiest way to do this would be to parallelize the ML training by doing something like openMP or even using a GPU enabled machine learning library but this is certainly not the case because the ML training is indeed tremendously fast. In a regular NN system execution process the ML takes only around 0.0053 seconds to execute meaning that any type of parallelization that you attempt to do will pay more in terms of data transfer over-head. The ML training ends up costing a lot because this process is repeated around 6700 times per 30 year back-test. Since we also perform mining in parallel – where all cores are in use executing an ML system instance each – there is little to gain from performing single strategy tests that use all cores instead of multi strategy tests with each strategy using a single core.
–

–
The ML training is done using the Shark library – which is already very efficient – so the best we can do to attempt to improve performance in this regard is to find the best possible compiler and compiler optimizations. Expanding on the research I had done before I actually found out that the clang compiler using the -O4 option is the fastest implementation I can get. Doing this I can reduce overall execution time by around 25% from a sample benchmark system taking 65.9 seconds to just 49.23. The overall share of the time spent in C decreases but the overall code improvement is rather similar along all the different C sections of the code.
The other thing we can do to improve performance is to actually reduce the input/output generation time dramatically. Thinking about this code section there is no need to actually reconstruct the input/output structure from zero when ML training is needed but you actually only need to add the last relevant example – since between executions there is at the most one new example to add to the input/output vectors – saving the arrays to thread safe local variables and simply appending the new example, shifting the array and removing the last one can change the overall input/output time cost from 18% of the F4 execution time to around only 0.6%. This reduces overall total execution time by another 11.6%.
I hope that with the above you have got a good idea of how our F4 trading framework and back-testing process work and how the execution time is divided within the process at least for some our machine learning strategies. As you can see this type of exercise is important to gauge where the most fruitful execution time reductions can be made and how they can be implemented. If you would like to learn more about the F4 framework and how you too can use it to code your machine learning strategies please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.




