Last week I wrote a post describing my initial journey into the world of machine learning strategies that took you from the time when I coded my first historically profitable machine learning system using neural networks to today’s setups using wide arrays of machine learning strategies derived from cloud mining efforts at Asirikuy. On today’s post I want to talk about the second part of this journey, which is the entire road ahead in the development of machine learning algorithms. Today we will talk about the problems with the current implementations, how they can potentially be improved and what new possibilities lie ahead in the world of machine learning strategies for the Forex market.
–
–
Right now all the machine learning strategies that we are trading live are derived from a general purpose framework using trade returns as inputs and trade outcomes as outputs. The system generation process is subjected to a data-mining bias assessment using our Asirikuy cloud mining setup and systems coming from generation processes where the DMB is below 1% are added to the machine learning repository as long as correlations with the reminder of the ML repository are below the R=0.5 mark. This setup offers us the ability to constantly generate new trading systems from the ML framework on a variety of different symbols. All these systems are constantly retraining strategies and all of them are computationally cheap to execute.
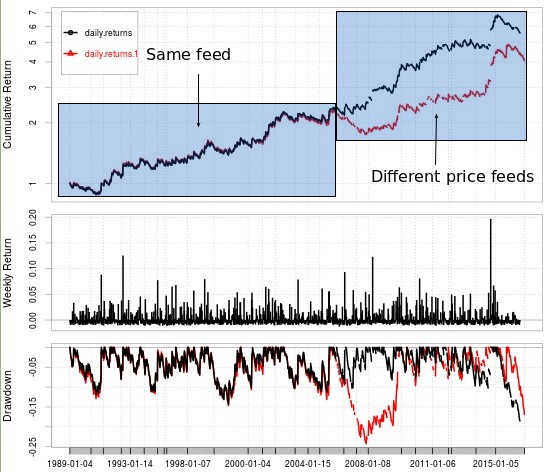
However the current machine learning algorithm we are using – despite being fast – has some important issues regarding its feed dependency. Linear regression has very limited degrees of freedom and it can lead to important differences in results depending on how your trading inputs are aligned. This means that if you are back-testing with one data set and then live trading with a completely different one you can expect to see some important distortions due to the historical differences between the feeds. All-in-all linear regression based machine learning has this issue that can only be completely overcome if you either use data from the exact same source for back-testing and live trading (at Asirikuy we try to overcome this by using Oanda data – the broker we use for live trading – as far back as possible to generate strategies). Either way this sensibility stemming from the properties of the machine learning algorithm are problematic and it would be best to use an algorithm that did not have these problems.
–
–
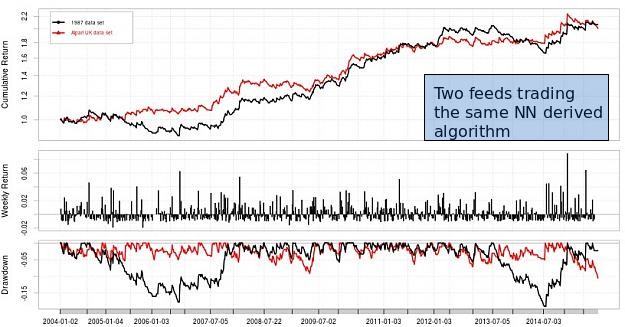
The first thing that comes to mind when improving our current machine learning repository is therefore to move to less feed dependent algorithms which – in my experience with ML algorithms – means to move to something that has more degrees of freedom and the ability to sustain non-linear behavior. This is because when training algorithms that are capable of non-linear behavior small changes in the examples cause less distortions in the overall predictions compared with an algorithm like a linear regression where small changes in inputs can cause very significant differences in the generated models. From the pool of algorithms that fulfill these characteristics neural networks are the most prominent but have the issue of being much more costly from a computational cost of view. However using some tricks we can make neural networks quite cheap and just a bit more expensive than linear regression algorithms while retaining their ability to express non-linear behavior and give results that are much less feed dependent.
Another important thing you can do to attempt to attenuate this issue is to change your inputs towards inputs that are far less variable than the general price feed. Although bar returns can change very easily just by introducing a few pip differences you can use things like the RSI or the CCI as inputs which are far more robust to changes since they are both bound oscillators and dependent only on a limited set of bar characteristics that do not necessarily change just because a bar closed or opened two pips higher or lower. Using other oscillators or indicators that compensate for this noise between feeds – such as moving averages – may also help improve our results in this sense. Combining indicators in inputs also allows for a whole new level of possibilities at the expense of more mining complexity.
–

–
Besides reducing dependency the use of indicators opens up an entire new window into machine learning as the inputs used are far more complex that what we currently use (which are just bar returns). I am intrigued by whether using indicators and trade outcomes can offer some improvements when using classifiers as machine learning algorithms. Classifiers have the advantage of being cheaper to calculate but suffer from issues in giving useful predictions since their training often becomes too simplistic as the number of cases considered is usually significantly reduced when compared to what a regression algorithm contemplates. However we might be able to get around this reduction by using a more extensive set of categories to describe trade outcomes instead of simply “profitable” and “not profitable” (which is what I have done in the past and failed with).
Besides all these improvements in the algorithms I am also looking forward to expand our technical mining capabilities, which will be needed if we want to incursion into the more expensive and potentially much more valuable machine learning algorithms. For this I have purchased a Xeon Phi card (like the one shown above) which I will experiment with once I buy a compatible motherboard in early January 2016. These boards have a ton of processing capabilities within an x86 architecture, allowing us to execute our back-testing software without the need of complex re-coding, something that is sadly needed if you want to use something like a GPU and very complicated if you want to translate an entire ML algo suite like the Shark library or another equivalent implementation. We are also currently looking into credit card sized computers like the ODROID-XU4 for the building of easily expandable machine learning mining rigs.
The future is looking to be very interesting as we venture more deeply into the creation of machine learning trading strategies and implement new technological solutions to solve problems and increase our mining capabilities. If you would like to learn more about machine learning and how you too can build machine learning strategies please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.




