It is no mystery that inputs are one of the cornerstones in the building of successful machine learning algorithms for trading. Inputs are in the end what will allow you to make successful predictions and using irrelevant, redundant or badly scaled inputs can make your algorithms complete useless. Today I want to talk a little bit about the inputs that I have used in the past and what inputs I am considering to use within my algorithms right now. Through this series of posts we will be talking about what makes an input relevant or irrelevant, what tools we have to create inputs and what can happen if the inputs we use are not adequate. I will also try to share with you some comparisons of different inputs so that you can see why they are different and why they can often lead to different successful algorithms in Forex trading.
–
–
Inputs are the sensory organs of your machine learning algorithm. As humans we have many different types of “inputs” that we use to navigate the world, inputs that are generated from our interaction with everything around us. Imagine that you’re not wearing any shoes and you step on a cold sheet of ice, the cells in your foot convert the heat transfer from your body to the ground into a series of electrical impulses which are used as inputs by your brain to process the information and come up with a given output, which would be taking your foot of the ground if you’re not into frostbite. In the case of a machine learning algorithm that trades we want to do something similar, be able to obtain some sort of sensory input that our algorithm can translate into a useful prediction.
If you want to predict future prices the first thing that you may have tried is price itself. Using price to predict price is the most naive and least useful approach. As anyone doing machine learning in trading quickly learns the price component is heavily auto-correlated and has little variation in small steps meaning that when you attempt to use pure price to predict price the machine learning algorithms conclude that the best estimator for price is the last price you measured. In the end this is true but there is no predictive benefit from being able to know that yesterday’s price is a good proxy for today’s price because you’re seeking to profit from a variation of prices that is usually far below the price variation in the bars you’re using for input construction. However you won’t be able to obtain good predictions using prices unless you jump through all sorts of hoops.
–
–
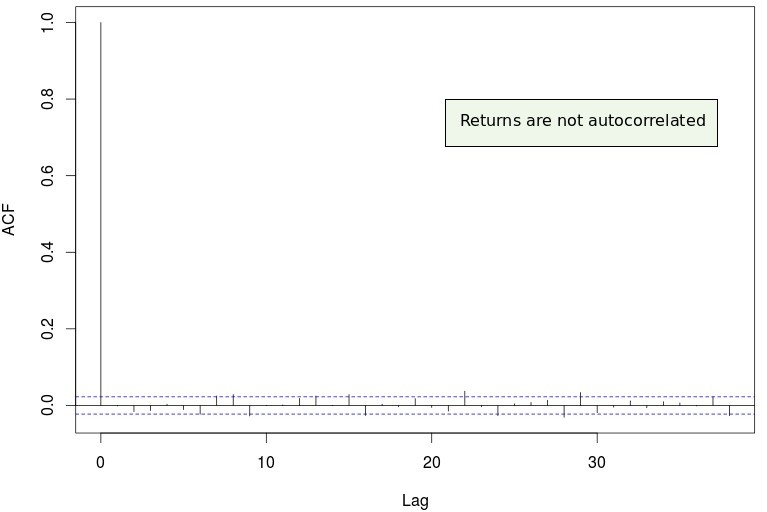
The next best thing – and a very difficult thing to beat – are the price derived returns. Returns are simply the difference between the current price and the last price divided by the last price – usually we use the close prices – and give you information that is pertinent exclusively to how the value of an financial time series has changed through time. Returns are not auto-correlated and extremely useful in the sense that you can actually use returns to create historically profitable machine learning systems. However there are a few other things that we can use to make predictions taking into account additional sources of information from the data we have available.
In regular returns you only use a single price value from OHLC candles to make calculations. This means that you’re eliminating 3 points in the OHLC chart that could potentially be useful for predictions. Here you can include returns based on each separate element of the series as a different input – thereby making your models more complicated – or you can actually try to create a series that synthesizes all 4 OHLC values and work from there. Thinks like the pivot points (C+H+L)/3 can be used to derive returns that include information from the high and low of a candle and other things like the Heiken Ashi candles can be used to derive returns that include the entire OHLC. For example using the Heiken Ashi close you can have (O+H+C+L)/4 which produces a series from where you can derive returns that contain contributions from the 4 points. That said there are a myriad of ways in which you can combine the OHLC. Nothing forbids you from doing O+L/2 or (O+H-L+C)/4.
–

–
Another thing you can consider is to do transformations over your data to obtain distributions that are in some ways “better behaved” for example you might consider using logarithmic returns (log(current price/last price)) instead of regular returns in order to obtain distributions that have somewhat less fat tails and are closer to normality. This makes things easier for machine learning algorithms as these type of algorithms usually have a hard time when you want to be right in cases that represent only a very small percentage of your sample (which is exactly what we want in trading). You can also perform tricks like scaling – just dividing or multiplying by a fixed amount – so that your algo can better deal with the data. Scaling can often increase convergence and greatly enhance the results of models like neural networks where input presentation is very important.
Time is also a key component in what you can learn from your data but it is important that you include it in a way that can distinguish that time has a categorical and not a scalar relationship with your intended outputs (which is most probably the case in trading). For example if you give a neural network a trading hour as input it will take it a lot of effort to find the non-linear relationships that make all trades taken at hour X different than those taken at hour Y. In contrast if you train 24 different neural networks – one for each hour using only inputs from that hour – you will find that your results will be much better. Similar tricks apply to other time properties such as the day of the month, the day of the week or the minute that you’re trading.
On the next post of these series we will talk more about how you can create inputs for your machine learning algorithms and what happens when you try to use inputs from different financial instruments to make predictions. We will also look deeper into example filtering and how this can also greatly improve trading results. If you would like to learn more about machine learning and how you too can build your own machine learning strategies using a powerful programming framework please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.





Hi Daniel,
I found this article interesting regarding profitable model-building :
https://www.quandl.com/blog/interview-with-a-quant-part-one
Hey,
Great article!
In fact, great blog!
Was wondering if the next article on this series is out? I am not able to find it.
Thanks for sharing.