Yesterday I spent the entire day – more than 10 hours – trying to solve a bug that showed up within our back-testing software at Asirikuy. Not only was this bug of a particularly puzzling nature but the fact that the code was done in C made the bug harder to solve. Coding in C to have much faster simulations does carry with it the price of having some issues that would extremely rarely show up in a language like python. On today’s post I want to tell you the story of what I went through when solving this bug and give you some potential advice on how to tackle difficult to solve problems like this in trading software. I will tell you the mistakes I made, how I finally managed to solve the problem and why it was such a nightmare.
–
while (strcmp(filenameString,"") == 0){
sprintf(filenameString, "%s%03d%03d%03d%03d.bin", pParams->tradeSymbol, (int)parameter(LEARNING_PERIOD), (int)parameter(BARS_USED), (int)parameter(FRONTIER), (int)parameter(ML_ALGO_TYPE));
}
f = NULL ;
while(f == NULL){
f=fopen(filenameString,"a+b");
}
writeOutput = 0;
while(writeOutput == 0){
writeOutput = fwrite(&ensemblePrediction,sizeof(ensemblePrediction),1,f);
if(writeOutput != 0){
f_close_reply = 1;
while (f_close_reply != 0){
f_close_reply = fclose(f);
}
f = NULL ;
while(f == NULL){
f=fopen(filenameString,"a+b");
}
}
}
f_close_reply = 1;
while (f_close_reply != 0){
f_close_reply = fclose(f);
}
–
This entire bug surfaced because I wanted to save binary files containing 8 bit integer values with the predictions of machine learning algorithms. There is nothing difficult in principle about doing this in C and it was as easy as using the code I am posting above within a machine learning system. The code has a lot of while statements that are not necessary in principle but I wanted to make absolutely sure that each prediction was written regardless of any odd errors that might show up within any of the functions. The above code ensures that things are retried until the filename is properly assigned, properly written to and properly closed. In essence you would expect the above to be an ironclad formula for writing a series of 8 bit integer values into a file. Then the bug showed up.
The bug was one of the weirdest programming bugs I have ever seen. When I launched a series of different machine learning systems with different parameters to save their predictions they should have all saved the same number of predictions so the file sizes should have been identical between the different systems. What happened was that I was getting some files with 158,114 predictions, the value I expected, and others with lower values going usually from 158,098 to 158,113. Changing to save the dates instead of the predictions showed that random bars were missing when doing the test, as if the program was not going through the entire set of data but was randomly deciding to skip some dates. This happened only rarely – as you can see just a handful of times in almost 160 thousand – which made it even harder to pinpoint. Trying to store the entire sets of arrays and then writing them yielded the same missing data problems as well.
–
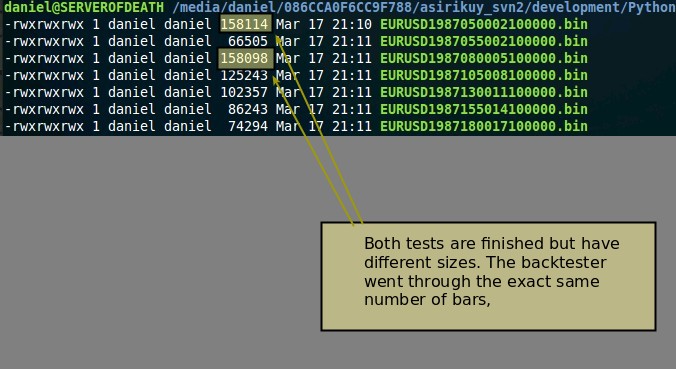
–
Further discussions at the Asirikuy forum showed that another Asirikuy member did not experience the problem on Windows and further tests confirmed that this only happened when things where being done in multi-core using OpenMP on Linux. This means that single threading worked perfectly well while multi-threading had the odd issue of skipping bars randomly – only a few through the entire test – due to an unknown reason. Those of you experienced in OpenMP may immediately think about some type of racing condition in the multi-threading – which is also what I thought – so I proceeded to debug the entire OpenMP implementation to see what might be wrong. Further tests showed that data was being passed correctly to the systems – so the function calling the strategies did get all bugs – so this made things even more puzzling. Where is the data getting lost? Is there a ghost in the machine?
After that I then decided to look at the bars received by the trading system functions right after the function call and I found out that all the actual dates were there and remained there till the end. The problem was not a missing date but the fact that the program was deciding to skip an execution for some reason. Looking more closely at the code I noticed a function that we use to filter whether a system is being called on an invalid trading day (saturday, holiday, etc) to avoid execution under these circumstances. http://antihousewife.com/2010/11/san-antonio-birthday-and-thanksgiving/ The function called the gmtime function which I was very thrilled to find is thread safe on windows but not thread safe on Linux. When we first implemented the F4 framework we did so initially on Windows, so we failed to see this problem back then. Since the gmtime function writes its result to a static global structure it was being corrupted by overwriting from multiple threads. This overwriting rarely caused an issue since the filter only became active on very specific values but it did so with a probability of around 1 in 30 thousand due to corruption, enough to cause discernible problem when doing what I was trying to do but not showing up on any smaller type of unit test.
–

–
Finally changing this function to gmtime_r on Linux solved the problem and allowed me to sleep. However the intricate nature of the issue showed the type of problems that you can get whenever you’re dealing with a low level programming language using a complex and large piece of software, especially when it comes to multi-threading. Generally you can perform small unit tests to ensure accuracy when you are using single-threaded libraries and you can even test multi-threading implementations in this way to a point but when you are doing multi-threading you can be screwed because conditions like the above may only show up when certain specific execution conditions are met. When I first tested the multi-threading implementation accuracy on Linux I did not see this issue because I wasn’t recording things on every bar and the few random missing executions did not happen to change trading system results (this would only happen if one of those small number of missed bars happened when a system made a trading decision, an even much lower probability).
If you’re doing multi-threading my advice would be to generate much more complex tests that really put your system to the test regarding data racing conditions. Tests that are very complex – where many things are stored – but things like file size between runs should be identical are good ways to test whether you are actually going through everything in the way you intended. Writing all the dates is even better in this sense because you can actually compare file contents to be identical and you can then catch racing conditions that may show up. However some multi-threading bugs – like that described – may only show up when you really stress the software using many cores, writing lots of data. Happily the suffering was all worth it and the code is now free of another X file bug. If you would like to learn more about our programming framework and how you too can perform optimizations using openMP and even MPI to use different computers please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.




