As you may have read on last week’s post about machine learning system mining using the GPU I have decided to pursue the use of GPU computing in order to speed up the finding and back-testing of machine learning based strategies at Asirikuy. After one week of working hard on this problem I am now happy to announce a new software release that will happen this week at Asirikuy which will be the GPU software we will be using for machine learning mining, pKantuML. This new software borrows part of its name from our pKantu software – used for the GPU based back-testing of price action based strategies – and provides similar functionality in that it takes our machine learning mining to an entirely new level. Today I will be taking about this new software, how it works, what it can do, the improvements it has achieved over its predecessor and how it will contribute to the building of new portfolios at Asirikuy.
–
–
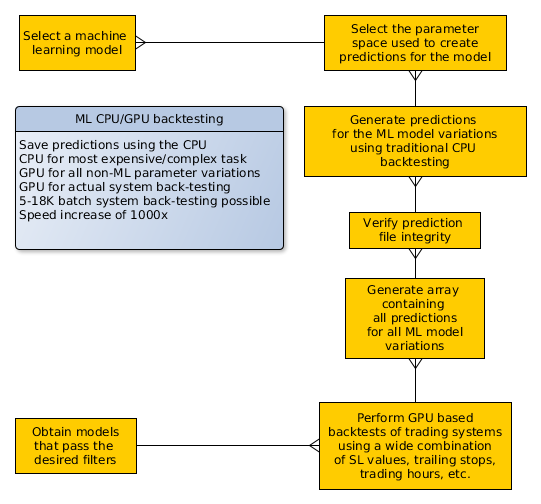
The pKantuML software is not a pure GPU based machine learning implementation. As a matter of fact implementing machine learning algorithms within GPU kernels to use them as we need to – perform a constantly retraining machine learning process within each GPU process on each GPU core – is extremely difficult and inefficient both due to the non-sequential memory access needed and the complexity of the machine learning model core. Instead of going down this nightmarish road – which is what we had thought about in the past – we simply decided to leave the machine learning part to the CPU and simply perform the back-testing variations that do not affect the ML process using the GPU. In the end it’s a hybrid implementation that does in the CPU what it does best – complex processes using complex libraries – and leaves to the GPU the task of performing the back-testing process itself, plus all parameter variations that do not affect the ML process. A flow diagram showing how the process works is showed above.
In order to build this program I coded new ML algorithms that do not contain any variables used within other parts of the training strategies. I coded a linear regression algorithm and a new neural network algorithm, both which make long/short signal decisions based on the relationship between the prediction of the maximum long and maximum short excursions at a given frontier. The machine learning algorithms therefore have only three parameters, the number of examples used for training, the number of input returns used per example and the frontier used for the output prediction.The algorithms constantly retrain and therefore we’re interested in saving the predictions they make after training on each bar such that those predictions can be used in the broader GPU based back-testing. By saving the predictions for different parameter variations of the ML algorithms we have access to a potentially large array of final ML systems.
–

–
For the first test I made I generated a prediction space of 540 machine learning algorithms (using different example numbers and different inputs per example at a constant frontier value). After generating the predictions arrays the program then creates a single array containing all predictions and generates all the system configurations that will be tested (which ML algorithm, with which other parameter variations) after this the system configurations, symbol rates and predictions are fed to the GPU which performs the back-tests for the strategies at lightning speeds. With 540 machine learning algorithm variations I ended up with a final space – including all non-ML parameter variations – of 39 million systems. These systems can then be back-tests at a speed of around 2.2ms per system on an i7 CPU (image above). This is because the openCL code used for these simulations is much faster than a regular back-tester. However the speeds improves even more dramatically when this is executed on proper GPU interfaces, allowing execution of strategies in the 0.2-0.5ms per system range.
Of course the main limiting step for the above process is the creation of the machine learning prediction arrays. Creating the 540 prediction files took nearly 6 hours using the 8 cores of an i7-4770K which means that the process is rather slow since it’s bound by the CPU (although it’s still quite fast if you consider that each file contains around 160K predictions and for each prediction you have to retrain and execute a machine learning algorithm). However consider that for proper data-mining bias analysis you need to repeat this step on random data and then you start to see how properly validating a machine learning result might still take up to around 1 month (since you need to repeat the mining on random data enough times as to converge the distribution of performance statistics expected from randomness). earthward However the big difference is that while before it would take us 1 month to mine a 10,000 system space, it will now take us the same time to mine a 39 million system space. This is a more than 3000 times increase in the actual productivity of the mining process.
–
–
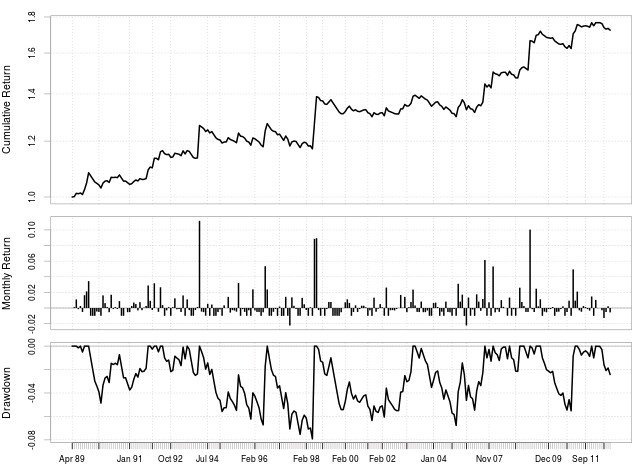
Of course the final test of this entire process is to take a system mined using pKantuML and test it within the F4 framework to see if the results are the same. This is what the above graph shows you where I have taken a machine learning learning strategy obtained from this mining exercise and back-tested it using the F4 framework. The results show that the back-testing on the GPU is accurate and that the systems mined do show the same statistics compared to those calculated within the OpenCL implementation. This 1000x increase in our ability to mine machine learning systems will definitely imply a much faster building of our machine learning portfolios. This week the pKantuML implementation will be released to the Asirikuy community and next week I will enable the cloud mining scripts that will allow us to start contributing to the pKantuML mining within the community. If you would like to learn more about machine learning in Forex and how you too can build machine learning strategies using our programming framework please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.




