During this month I have focused on the exploration of trading systems based on Q-learning and have now developed a basic understanding of how state definitions work and how they can be used for the construction of trading systems that learn optimal policies from past data and continue adapting as trading continues. In order to prepare for the mining and trading of Q-learning based strategies I have also decided to develop a general system in F4 for the loading of Q-learning strategy definitions that is able to benefit from many of the advancements we have made in the development of the pKantu and pKantuML projects. On today’s post I want to talk a bit about this implementation, how it works and how it will fit into the Q-learning mining vision that I am developing for Asirikuy.
–
–
When developing reinforcement learning strategies one of the first things you must do is decide how you will define market states. The definition of these states represents the most important decision you will be making as the richness and actual content of your states will define how much can be learnt from the learning process and whether this information will or will not be relevant going forward. For example you can use the positions of astronomical bodies to define the state of the market at each different point in time. Your algorithm will then learn things such as: if I am in a state where the planet positions are A, then buy. This will work in the training period provided you define enough astronomical bodies to have enough degrees of freedom but it will most certainly fail when you trade it going forward, because astronomical have nothing to do with trading.
The main problem to solve in reinforcement learning then becomes to select information for the construction of market states, such that the information selected is really relevant to what you want to predict. Since any source of varying information will tend to work – you can create 20 random variables that are pure white noise and learn from them successfully in historical data (a future post) – you need to make sure that you can perform significantly better than what Q-learning on random data could offer you. As you might correctly assume doing these tests will involve doing potentially thousands of different tries using different system state definitions and it therefore becomes critical to be able to have some implementation that allows you to easily change this.
–
–
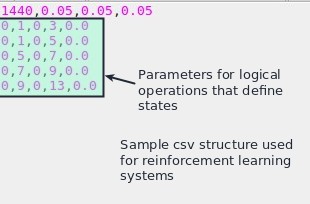
For this I decided to create a system using binary representations of logical operations put together into integers as my state definition mechanism. The logical operations are defined as simple price action comparisons of the form OHLC[A] – OHLC[B] > X*ATR where we have 5 variables, the choice of OHLC within the first and second price points, the value of the shifts A and B and the X multiplier that controls the ATR threshold. You could have a state that is defined by three comparisons O[1] – O[2] > 0*ATR , O[2] – O[3] > 0*ATR and O[3]-O[4] > 0*ATR which could have up to 2³ possible values. This means that we would have a number between 0 and 7 for a total of 8 different possible market states. The number of states is controlled by 2^N where N is the number of logical operations that help you define the state.
The F4 implementation I have made allows for the flexible loading of all the above quantities from csv files, allowing for a dynamic allocation of any number of reinforcement learning system definitions. In addition to this each csv file also contains information about the alpha, gamma and reward modifiers used in each systems (more on these values in a future post as well) which allows you to have algorithms with the same state definitions that perform learning at different speeds and also use rewards that have different magnitudes. This is the first step in the mining of reinforcement learning systems, which is a simple mechanism for their loading, back-testing and live trading. The next step is to implement GPU-based reinforcement learning that perform the entire training/testing process and that also performs the same process on random data sets in order to ensure that the positive results we get are not simply due to the mining bias we’re introducing by performing large-scale computations.
–

–
All the above mentioned F4 code implementations will be available from today for all Asirikuy members. If you would like to learn more about supervised machine learning and reinforcement learning in trading and how you too can build your own strategies using these approaches please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.strategies.




