From the time when I first started to design Forex automated trading systems it became apparent to me that the task didn’t have the same difficulty on all the different currency pairs. While I could easily come up with systems that gave profitable historical results on the EUR/USD, designing systems for something like the EUR/JPY or the USD/CAD was a whole different story, even though I was using similar development methodologies. In analogy it seemed that systems designed for the EUR/USD were more profitable in out-of-sample (in live trading) than those designed for less liquid pairs. It is therefore interesting to ask if there is a fundamental difference between these pairs. Are some pairs “more inefficient” than others? Today I want to answer this question from an entirely quantitative perspective, thanks to the research I have been able to carry out using the Kantu system generator software. On today’s post you will learn why the EUR/USD is more inefficient and how pairs should be evaluated before we develop automatic trading system generation methodologies for them. buy modafinil cheap uk On a side note I would also like to thank Fd for all his help with R scripts and with the analysis of some of the data presented on today’s post.
The question of whether it is best to design systems for one pair or another is not easy to answer. Many people will say that the ability to develop systems on one pair rather than another stems from personal bias and skills rather than from an innate difference between the pairs that makes system development “easier or harder”. In order to void the human development factor and put the question in quantitative terms I want to find out whether in-sample profitable and symmetric strategies generated automatically on one pair have a higher probability of being profitable in out-of-sample than strategies generated on another pair. The procedure to get this information is pretty straightforward with Kantu; I first generated 20,000 historically profitable and symmetric systems on each different pair with random 9/3 in/out of sample period going from 1987 to 2012 and I then compared the results with another pair. So one of the systems may have had an in sample period from 01.Jan.2000-01.Jan.2009 with an out of sample from 01.Jan.2009-01.Jan.2012 while another system might have gone from 1996 to 2005 in sample and then from 2005 to 2008 in out of sample. The randomization of the in/out of sample periods is fundamental to get a “full picture” of the currency pairs. Simulations included spreads as well as random slippage.
–
–
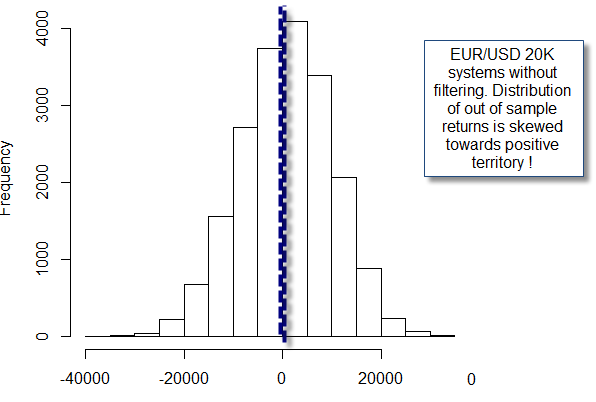
After we get the results we can then proceed to draw a distribution of out of sample returns that shows us the frequency (amount of systems) for each out of sample return class. As you can see in the image above (EUR/USD results) the out of sample returns tend to form a bell-shaped curve with the interesting fact that the curve is skewed towards positive territory. This means that if we generate a profitable and symmetric strategy on the EUR/USD we have a more than random chance of being profitable in out of sample regardless of the in-sample statistics. In the case of this pair it is enough to have something that is historically reasonable (profitable and symmetric through in-sample trading) to have an above chance expectation of positive performance for the next 3 years. In other words the EUR/USD is inefficient because we can get profitable out of sample results based on historical in-sample performance. This definitely explains why I always found it easier to optimize and create new systems on the EUR/USD and it also explains why neural networks tend to do so much better on this pair than on others. http://rhythmsfitness.com/beence.php Note that the edge we have above is both regarding the number of profitable systems in out of sample (About 600 more than predicted if we had no edge) and total net addition of all profits and losses (meaning that the sum of all the out of sample results is positive).
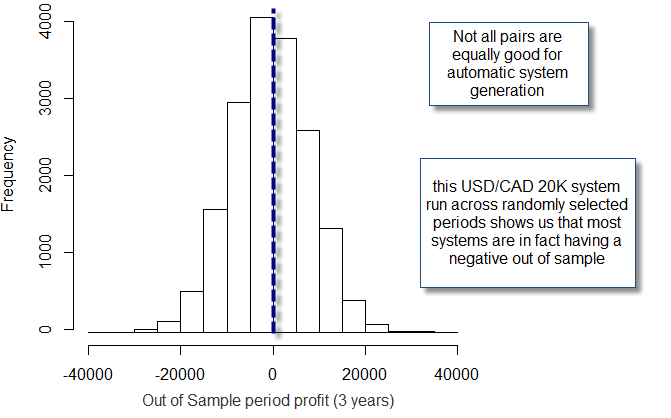
What happens when we look at another pair, such as the USD/CAD (which I have always had problems with). What we find is that the distribution of returns has changed and is now centred around negative territory. This means that profitable symmetric in-sample results were not enough to give you an edge on this pair during the past 25 years. The USD/CAD is therefore less inefficient than the EUR/USD because designing systems that give a positive expectation for out of sample profitability is simply harder as there are far more good in-sample strategies that fail in the out of sample when compared to the EUR/USD. This is a quantitative comparison of currency pair efficiency based on parameterless price action based pattern generation, giving us a very important clue about why designing systems for minors such as the USD/CAD might not be the easiest or most profitable idea. In fact if you try a system generation procedure where you select the most highly correlated in-sample performance variable with out of sample performance as your selection criteria you will see that results are always profitable for the EUR/USD while they are always losing for the USD/CAD (more on this methodology on a future post).
–
–
Why is there such a big difference between these pairs? My main explanation for this is a complete negation of the efficient market hypothesis (which we know is wrong, particularly since the strong failure of random walk based volatility prediction models during the financial crisis). My vision is that traders are not rational profit maximizers – as the efficient market hypothesis says – but that traders are in fact emotional and irrational and therefore higher volume leads to higher inefficiencies because there is a higher manifestation of the underlying human nature that makes the markets predictable to a certain degree. This means that an instrument will be easier to exploit if it has a higher trading volume, something that is confirmed when you analyse the other majors and minors which shows you a direct relationship between average yearly trading volume and the skewness of the out of sample distribution of returns derived by Kantu.
The conclusion is that it is far easier and potentially far more profitable to trade highly liquid pairs (at least algorithmically) than to trade minors or exotics. Although this doesn’t mean that profitable trading on these pairs is impossible – I’ll show you a way to do it on a future post – it is indeed telling us that there are pairs where it is easier and more practical to develop trading methodologies. This also has consequences for automatic system generation because it means that although we might be able to find profitable in-sample results for all pairs, only on some pairs will these systems tend to give profitable out of sample performance. Therefore the previous analysis of a pair’s efficiency is fundamental to determine whether algorithmic system generation is the correct approach or what modifications might be necessary to make it so.
If you would like to learn more about Kantu and how you too can develop algorithmic systems automatically please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





How did you go about generating “20,000 historically profitable and symmetric systems on each different pair” for your analysis?
I used Kantu, our parameterless price action based system generator :o)
Hey Daniel,
How do non-currency instruments compare with currencies in terms of efficiency?
Hi Igor,
That’s a good question but sadly Kantu doesn’t support non-currency instruments — yet. Support will be added soon. Thanks again for posting!
Best Regards,
Daniel
Hi Daniel,
following your theory of system profitability being linked to liquidity, did you try kantu on also high liquid pairs like USDJPY? Based on my experience I have the feeling that you can throw any subpar trading system to EURUSD and it ends up making money in a 10 years backtest…
Cheers,
Daniel
Hi Daniel,
Thank you for your comment :o) I have in fact tried measuring profitability in the same way for the USDJPY/GBPUSD/USDCAD. The results are extremely interesting but are reserved for a later post! However I can tell you that your instincts are right, the EUR/USD is a much easier pair to develop systems for (and I will further confirm this quantitatively going forward). Thanks again for posting,
Best Regards,
Daniel
PS: Calculating logarithmic fits for other pairs (as I did for the EUR/USD on this post) we can derive an inefficiency coefficient that tells you how easy or hard it is to trade profitably on one pair using system generation (stay tuned!).