On yesterday’s post we discussed some of the main characteristics of data-mining bias as well as the parameters that we will be using to calculate an example of this value using Kantu — an exercise you can repeat at home to compare with me. If you haven’t done so already I would recommend you read this post before you continue. On today’s post we are going to look at the results from this analysis and see what conclusions we can draw from them, we will see what system statistics Kantu was able to obtain on random data – for the data lengths and degrees of freedom chosen – and we will compare them with the statistics obtained for systems obtained within real data. In the end we will be able to obtain a measure of data-mining bias and this will allow us to have some minimal criteria for the selection and discrimination of trading strategies within the data-mining process.
–
–
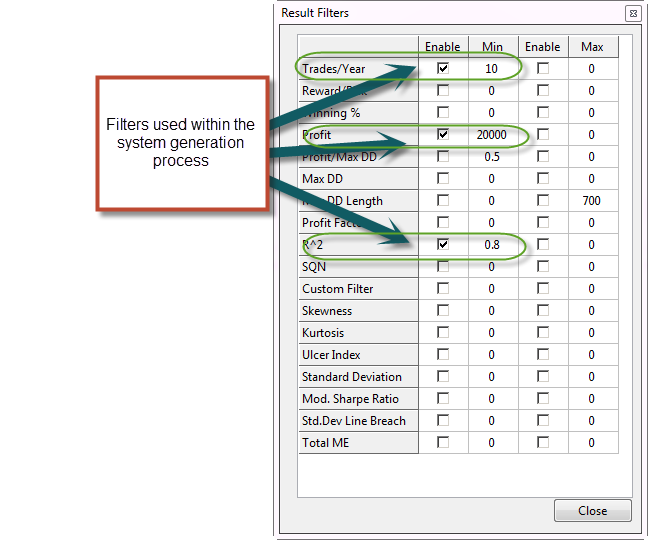
The overall analysis took a bit more than 2 days to complete, it went through 120 million systems on the random data (which should cover a very large portion of the logic space, if not all of it) and generated some strategies. It is worth noting that I introduced some filters within this analysis as I was clearly not interested in looking at the results of strategies that were below a certain degree of profitability. In order to obtain a good amount of systems but still have less than tens of thousands I decided to filter systems with less than 10 trades/year, a 1% Average Annualized Return and a 0.8 linear regression correlation coefficient (R squared). Systems below these marks are clearly very bad systems that are barely profitable or very unstable through time, reason why I wanted to ignore them. Through the whole analysis I collected about 1500 system results, which we are going to use in order to determine our data mining bias.
The strategies obtained through this process (sorted by absolute profit/year to maximum drawdown as percentage of initial capital ratio a.k.a Profit.Max.DD) are clearly limited to values of the Profit.Max.DD of less than 0.27. Even after a very extensive amount of data mining the Kantu system generator was unable to find any system that went above this possibility. The absolute profit is also limited to about 50,000 USD which in Kantu (which uses non-compounding simulations), means that the systems would achieve an Annualized Average Return (AAR) of about 2-2.5%. The Max.DD.Length statistic also shows a significant limit near the 950 day mark as no system with a drawdown length below 950 days was produced. Linearity however is not a good criteria for the distinguishing of spurious correlations on its own as highly linear systems (R^2 > 0.98) were produced as well. It is also worth noting that this analysis was repeated across 4 random data series as well as 2 additional random data series were returns were produced using the mean of the EUR/USD return distribution (instead of 0) which yielded very similar results (statistics limited to the same values). You can use the R-scripts below to obtain the same graphs using the csv saved from the Kantu results grid (right click, save results as csv).
–
dataset <- read.csv("E:/PathToResults/RESUTLS.csv")
head(dataset)
par(mfrow=c(2,2))
plot(dataset$Profit.Max.DD)
plot(dataset$Abs..Profit)
plot(dataset$Max.DD.Length)
plot(dataset$R.2)
–

–
After this analysis it is clear that the Max.DD.Length and Profit.Max.DD statistics give us the best opportunity to clearly distinguish a system that is produced due to some real price inefficiency rather than some spurious correlation. If we look for systems above the 0.27 Profit.Max.DD ratio and a Max.DD.Length below 950 days – on 25 year back-tests – we are bound to find strategies that are in most likelihood the result of some real effect within our financial time series. To be sure we should go well above these values, for example to 0.4 and 750 days. Note that this doesn’t mean that these strategies will be generating profit in the future – as the future is unknown – but simply that these systems are the result of some real historical difference between the real financial time series and random data. Whether this difference is permanent or will change cannot be known in advance (or we would all be rich :o)). What is known here is simply that this inefficiency constitutes a historically valid effect that could not be found on random data with the given degrees of freedom. Remember that the data-mining bias depends on your degrees of freedom in the data-mining process and therefore a new analysis needs to be carried out if this changes.
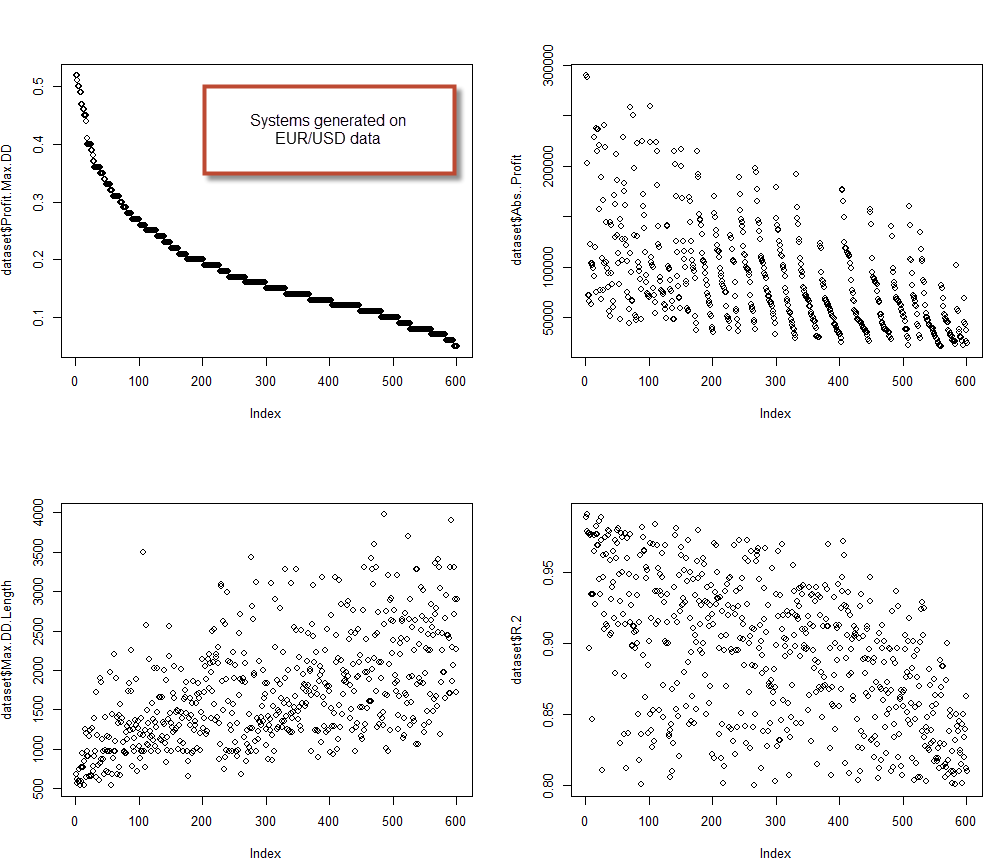
The next step is to see whether we can generate systems on the EUR/USD that exceed these thresholds. I generated 600 systems using the same thresholds as on the random data, this was actually done within a few minutes while on the random data it took days. The systems generated also have very favorable statistics. From these systems 3% exceeded the Profit.Max.DD of 0.4, while 4.5% had Max.DD.Length below the 750 day mark. Knowing this we can further analyse these systems and discard those that have low linear regression coefficients, to stay only with those that show high historical stability. This shows that the EUR/USD can produce systems that are far more profitable and have less drawdown than systems produced in a financial time series with the same mean and standard deviation. You can see on the two images that there are some obvious difference between systems created on the EUR/USD and systems created on random data. For example the maximum profitability for EUR/USD systems also exceeds a 15% AAR, about 7 times higher than for the random data.
–
–
When generating systems with these degrees of freedom I now know that I can put up the Profit.Max.DD and Max.DD.Length filters in advance – as my data-mining bias – and obtain systems that are well beyond what is expected for random financial data. The next question to ask is whether this bias is different or the same as what can be obtained using random variables on the real financial time series. Can I still obtain systems that have above-data-mining bias results using randomly generated variables for testing? Within the next post on this series we are going to look at random variable generation on real financial time series to see if we can still find a spurious correlation that produces results above the data-mining bias.
If you would like to learn more about the data-mining process and how you too can generate your own systems using the Kantu system generator please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





Hi Daniel,
This is good and detailed work but I have some suggestions because your posts are long and involved:
A. It would be good to summarize your finding in the beginning of the article in the form of an abstract or summary and then discuss them in a conclusions.
B.It would also be good to use a standard metric to compare results that is known to be normally distributed – for example the mean return. Drawdown and profit usually depend on money management.
C. Besides the data-mining issue there is also a curve-fitting issue. A curve-fitted system will always look good. How do you account for that in this study?
Hi Bob,
Thanks for your comment :o) Let me answer your points:
A. Let me think about a way to implement this :o)
B. It’s also a good idea, I’ll take into account these statistics on future posts.
C. Well the run on the random data has the same ability to curve fit as the systems on the real data (both tests are executed with the same degree of freedom) so I would say that the measurement of the data-mining bias also contains this as well. Let me know if I misunderstood what you meant.
Thanks again for commenting bob :o)
Best Regards,
Daniel
Hi Daniel
I’m in fact very skeptical about this exercise, even if the idea is quite interesting in theory. At the end of the day I don’t think the results will be useful. The first thing one is interested is in finding a system that will probably perform well in the future, a system that is able to adapt to varying market conditions. I don’t see how one can increase the likelihood of that by comparing a “real” system with a system generated with random data.
Plus, those systems with the best performances are in fact the ones more prone to be suffering from over-optimization. So, the fact that a “real” system performs better than system generated with random data says nothing about it! In fact it would be quite surprising if it happened the other way around! Who would choose a system yielding less that 2% a year or with a large drawdown?
What I mean therefore is that probably this exercise will not bring added value comparing to the the existing methods of selecting systems.
We’ve been exchanging emails and I find the avenue of comparing IS with OS indicators more interesting. From my preliminary analysis, only on EURUSD and GBPUSD, the standard deviation of returns and the max. drawdown (the less, the better) appear to be variables with some capability of predicting higher OS profit factors and lower drawdowns.
Anyway I hope you prove me wrong and I’ll keep reading your (very interesting and challenging!) posts.
Nuno
Hi Daniel,
Thanks for your comment Nuno :o) Let me now comment a bit on the things you’ve said:
This has nothing to do with whether a system will or will not perform better in the future. It’s simply an exercise to know whether you have found a system that corresponds to a real historical market inefficiency or whether it can be attributed to random chance. By calculating your data-mining bias you can be confident to a high degree that what you’ve generated corresponds to some historically relevant characteristic of the price series.
This post has nothing to do about selection for live trading, it is just showing a way to distinguish spurious from real historical correlations in the financial data series.
The problem with this is that your OS always ends up becoming an IS. If you look long and hard enough you will always be able to find some variable or combination of variables that offers some IS/OS correlation, you can always analyze IS/OS pairs long enough to come to some conclusion in this regard. When using a data-mining process there is no such thing as an OS because you can run a very wide array of IS/OS tests and eventually find something that works. Your own experience acquired by doing these tests generates a bias problem in your findings. In fact if you look at distinct historical periods the IS/OS correlations will change significantly, in my experience conclusions from such IS/OS analysis are also of limited value and sometimes they fail dramatically. For example if you do an IS/OS analysis of the USD/JPY before 2004 you’ll find some IS/OS correlations that completely fall apart on later periods. Sometimes IS/OS correlations show because the past (IS) and the future (OS) are similar but sometimes the future changes and the IS/OS correlations fall apart. Be careful when playing the IS/OS correlation game it can lead you to some dangerous assumptions.
Thanks a lot again for your comment Nuno :o) I’m always happy to hear different opinions and use them to better construct my analysis and articles. Keep the comments coming!
Best Regards,
Daniel
Here’s a recent blog post by Michael Harris that seems to support Daniel’s research
mikko
And here’s the link that I forgot
http://www.priceactionlab.com/Blog/2014/01/analysis-of-the-timing-ability-of-a-machine-designed-trading-system/
Ha ha now that was tough pasting the link in but third time’s the charm :-)
Thanks for the info Mikko. I’m not sure I fully understand what he does in this analysis but I’m more interested about the analysis in another recent post about a forex system http://www.priceactionlab.com/Blog/2014/01/price-action-lab-gbpusd-system-performance-in-2013/
Specifically I’m interested in the part where the talks about random system and ranks the performance of his GBPUSD system (frequency distribution). This is an interesting approach but I have to think about it more.
Hi Daniel,
Just a quick note to say how good it is to see you blogging these great articles again.
Cheers
Hello Daniel , as usual congratulations for your efforts.
In my humble opinion, an approach to algorithmic trading that takes into account statistical factors for extrapolates an EA , it is like putting the cart before the horse (curve fitting)
Personally i’m trying to trade since several years and I understand the ” crazy and volatile nature ” of this market that puts a strain on the patience and the emotions of a trader to be profitable in the long term must be a real hero.
That is why I shifted the focus to algorithmic trading and although I understand the limitations (an EA cannot decide in a rational and dynamic way in all different market situations at every moment as ” not feel the markets” ) , I believe (or at least I hope) which is still possibile build a deterministic strategy that puts us on the path of sustainable success (ie low level of stress)
We must start from choosing concepts that are EVER valid in the markets (what ALWAYS worked over time?)
We should starts with these concepts to enter in a trade and then refines the EA in deciding the trade management / money management (this is the real HOLY GRAIL)adding statistical concepts that we’ve seen make it less vulnerable over the time (for example from statistical point of view, like you said, trailing stop is going to makes less vulnerable over the time our EA ..
We do not need to build hundred EA and hope that someone is in profit.
We need only 3-4 good strategies that work well in combination in a way that we can sleep like a baby and and have the maximum comfort zone..
Hi Carmine,
Thanks a lot for commenting :o)
Bear in mind that this is no guarantee that any system will not fail, despite of how profitable or old it is. There have been systems that worked for 10+ years under live trading that then simply stopped working because something changed in the market. I would say that – as it tends to be – things are not that simple. There is no deterministic system you can build that will “always work” and there is no “better” way to build entries based on concepts that seem sound to our brains like “build a trend follower”. Things like this may have worked very well in the 70s but now things require a lot of additional effort – when doing either data-mining or manual building – in algorithmic trading (if you wish to have a higher reward for the risk you’re taking). http://childpsychiatryassociates.com/treatment-team/kathryn-cobb-stoner/kathy_stoner-600/ Even if you have 3-4 systems that have worked (even for 25 years in live trading), they will all fail, sooner or later but they all will eventually (they may also become so bad – like the turtle systems – that they stop becoming attractive because their drawdowns periods become too long, deep, etc).
Thanks to computers and statistics it is now possible to do data-mining, analyse system statistics, determine data-mining bias and build strategies that have a good chance of working out. Furthermore these strategies can be tested for failure constantly using statistical methods and they can be easily replaced by newly mined systems when they fail. It’s a lot of hard work, constant vigilance and a constant search for new methods and development strategies. You can sleep very well, but you have to work a lot! Thanks again for commenting,
Best Regards,
Daniel
Hi Daniel , thanks for your kind reply
I was not referring to a trend following system, in fact I agree with you on this ( I have documented enough on this) this kind of systems suffer from the fact that the trend may not have the right magnitude and strength to perform well in some periods.. I was referring to some kind of ” contrarian strategy ” in the direction of the main trend (see Hidden Divergences for example)
I was wondering how you behave in this regard with your investments, if you spread the overall capital on many EA or you’re focused on a few EAs of your confidence , I ask this because I read so many articles on this site and I learn that you have developed a great amount of EAs and it seems too confusing and dispersed share capital on too many EAs.
Thank you for all your interesting articles, this is the first site that comes to EAs in a professional and serious approach.
Regards
Hi Carmine,
Thanks for your reply :o) I wasn’t referring to trend following specifically but simply gave it as an example. A “contrarian strategy” is just a different definition of the same type. What I mean is that an entry designed through a human perception is not more or less valid than a strategy created algorithmically. In the end all systems will fail so you need to have strategies for replacement and scoring of your systems.
About my behavior regarding investments, I reserve this insights for the Asirikuy.com community. If you’re a member please feel free to ask on the forum and I’ll be happy to answer with more detail. Again thanks a lot for your reply and for reading my blog :o)
Best Regards,
Daniel