It might be tempting to think that data-mining bias is the only important characteristic when automatically searching for strategies to trade in the Forex market. After all, if you have built a strategy that has an extremely small chance to come from randomness, you should rest assured that you have found something that is historically real and therefore useful to trade in the real world. However, the world of Forex trading is mined with some additional problems inherent to the Over-the-counter nature of the market, that make the data-mining exercise even more complicated than we would expect from a market with an exchange regulated history. In Forex trading you also need to worry about the accuracy of your trading history as you may have mined for something that is in fact historically real – as far as the history you’re using goes – but which may not actually be real when looking at the actual, real history from the market. On today’s article I will discuss this issue, give you some pointers on how to tackle it and finally show you why the multiple feed verification process is so fundamental to data-mining in Forex trading.
–
–
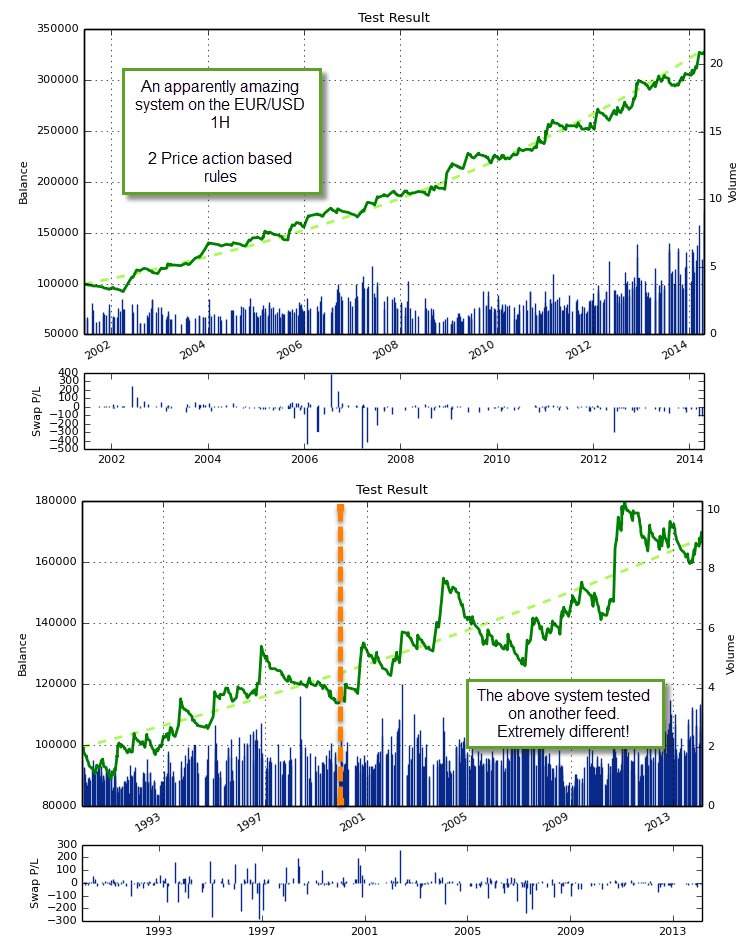
You’re very happy, you have done your due diligence to determine data-mining bias, you have searched for systems and you have found a gem with a very high profit, a really small drawdown and a very small probability to have come from randomness. You are happy to see that you have created a system worth trading that – if everything goes as planned – should go a long way in ensuring your success as a Forex trader. However something appears to be wrong when you start trading the system live, it starts to behave oddly and the results do not seem to match your back-testing data. Upon running a back-test for your strategy with another data source, you find that your excellent system is now a very poor performer with a high chance to come from randomness. What the hell happened?
Forex happened! In an over-the-counter market, historical data sources are sadly not unique and different historical data sources may have different peculiarities that are inherited from their origin. These peculiarities may include things such as the time when swap is charged/credited, tick filtering algorithms, or the fact that the data is actually consolidated across a couple of feeds instead of belonging to a single stream of currency data. All of these issues might create artifacts that are terribly specific to a particular data source which – when mining – leads you to find very specific real historical inefficiencies for your data that are in fact not that real in the overall Forex market. For example your data might come from a broker with a strong tick filtering algorithm that removes some market spikes that happened across the real market, avoiding the touching of certain levels. Trading at times where this happened may constitute an advantage across that particular historical source, when in reality it does not.
The above problems are also not the same across all tests. High timeframes (12H, daily, weekly, monthly) rarely suffer from a significant influence from these tests – although it can still happen to some degree – while on the 1H charts the influence is incredibly strong. When mining for systems in the 1H you can easily find systems with apparently amazing statistical characteristics that are achieved due to the exploitation of some feed specific features that are not an overall characteristic of the market. Testing on two different feeds from separate sources largely eliminates the profit from these artifacts because it would be strange for two separate feeds to contain the same types of peculiarities. The artifacts of one feed will compete with those of the other and finally you will come up with systems that are only profitable across both. The probability that you have an artifact is now much lower, because it would have to be something common to two completely different feeds.
–
–
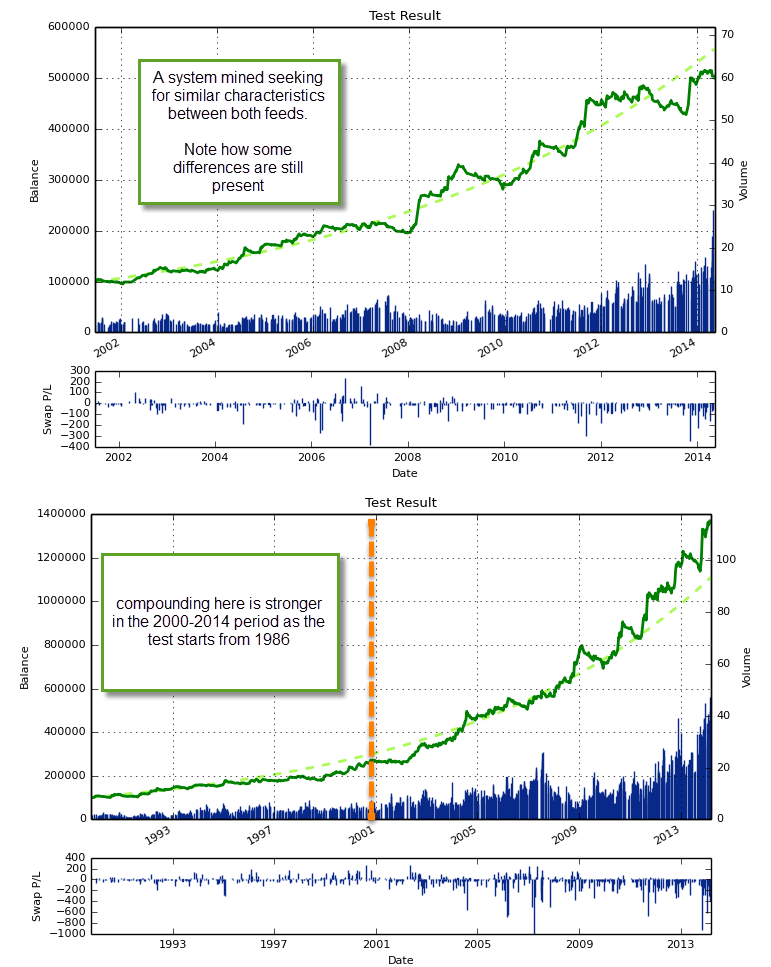
While the above does not guarantee a lack of play involving feed artifacts (as they might still play some influence on their respective feed) it does smooth out the results such that the main inefficiency exploited by your system will be mainly attributed to some real characteristic of the global Forex data. For example the above system shows a system mined across two feeds that has similar statistical performance across both of them on the 2000-2014 period. Although the trade results are not exactly the same across both feeds, they now do match a lot closer than for the initial system showed above, where obvious and large differences between both of the feeds were present. Since there is no central exchange in Forex trading, system validation across multiple feeds is of the utmost importance when building systems, especially on timeframes below the 1D.
If you would like to learn more about system building and how you too can automatically mine for systems taking adequate precautions against data-mining bias please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





Is 2 feeds enough though??
Well, the more the merrier! With 2 feeds at least you ensure that you do not depend too strongly on any one artifact but I would say that ideally you would want to have more. Obviously finding data sources going back 10 years is quite hard so finding 3 or 4 is probably not viable.
wouldn’t be easier to use a good feed like bloomberg/iqfeed etc. so there will not be a need for 2 feeds???
There is no “good feed” in FX, because it’s an over-the-counter market. The lack of a central exchange means that no one feed represents the “real market” more accurately. Perhaps bloomberg feeds might be a very bad choice if your broker uses different liquidity providers. If there was a “good feed” (if we had a central exchange) things would be much easier :o)
Daniel to overcome the issue related about different feeds in forex, don’t you think it could be a good idea to move toward currency futures market since it’s regulated ? I have no experience at all trading futures , maybe some due diligence could be done to check if it’s doable as we do with forex in Asirikuy.
Regards,
Giacomo
Hi Giacomo,
Thanks for writing :o) Yes, it would solve the problem! However margin requirements are much larger. I would therefore be more interested in testing things in FX until we have a solid methodology and then move to futures with the +10K that we would need to trade there. Definitely for larger money I would be more interested in futures Vs Forex but FX is simply a cheaper ground to experiment. Thanks again for commenting :o)
Best Regards,
Daniel
Hi Daniel.
One question, how many users the Asirikuy website community currently have?
I have to finish some works before subscribe to Asirikuy, but I hope to join it next month, probably the at the end of June.
I really enjoy reading your work. Keep going.
Regards.
Hi Francisco,
Thanks for writing :o) Our community currently has more than 300 members. We’ll look forward to count you among our member!
Best Regards,
Daniel
Daniel.
I’m waiting for your next post, you have published really good material here.
I wish to know your opinion about WEKA for data mining?
Regards.
Hi Francisco,
Thanks for posting :o) WEKA is java and java is too slow for any serious mining, if you want to search systems across large logic spaces and – furthermore – perform DMB analysis based on random-data mining then things such as WEKA are simply not an option (not fast enough). Perhaps under some constraints it can work well (I have no experience with WEKA) but I would say that it is a highly sub-optimal option. Thanks again for writing,
Best Regards,
Daniel
Hi Daniel,
If you train and trade live using the same Broker, then wouldn’t the risk you discuss in this post be mitigated?
For example – train a liner model using 1 HR bars from FXCM historical data from 2005-present, then live trade on FXCM.
You said “When mining for systems in the 1H you can easily find systems with apparently amazing statistical characteristics that are achieved due to the exploitation of some feed specific features that are not an overall characteristic of the market.”
Why not exploit feed specific features if you are training and live trading using the same feed?
That said, it does intuitively make sense that your model will be more likely to be profitable by backtesting against multiple feeds. Good idea.
Also, is your web site Asirikuy down? I get sent to Verizon when trying to access it.
Hi Eric,
Thanks for writing. Well, it would indeed mitigate the risk but you have two main problems with this. The first is that it’s difficult to find 10+ year data for a single broker to perform data-mining, the second is that you would be vulnerable to your broker changing their liquidity providers and therefore changing their own data structure. Using several data sets brings robustness not only against using a historical data feed that is different from your broker’s but against possible changes in your broker’s data generated by liquidity providers. If you can, however, do include your broker’s own feed within the data-mining process.
Your second question regarding the exploitation of feed specific features is also answered in part by the above (what if the feed changes?) but you could also say that some of these feed specific features may be related with post-trading corrections or filters carried out by the broker after-the-fact so some of them may in fact not even be available when live trading. It is also possible that you’re just seeing artifacts that generate profitability due to a lack of enough resolution in simulations (for example a lack of proper broker-specific spread widening and slippage).
About the website it is temporarily down (some DNS issues with the hosting provider) but everything should be back up soon :o) Please try again tomorrow. Thanks a lot again for commenting,
Best Regards,
Daniel
Thanks Daniel! I’m very impressed with your blog and look forward to exploring your web site.
I researched FXCM and since 2007 they use a No Dealing Desk (NDD). Could this possibly reduce the liquidy provider risk you mention? – Since the NDD is basically polling the best bid and ask from a number of providers – thereby providing a more accurate market price.
From FXCM:
“In the NDD model, FXCM acts as a price aggregator. Once a mark-up is added, we take the best available bid and best ask prices from our liquidity providers and stream those prices to the platforms we provide. That’s the price you see. FXCM’s liquidity providers include global banks, financial institutions, and other market makers. This large, diverse group of liquidity providers is one of the things that make this model special.
When you trade with a standard Dealing Desk, you may not know where the prices are coming from or if they actually reflect prices in the broader market. FXCM’s deep and diverse pool of liquidity providers helps to ensure that NDD prices are reliable – not set by a single provider – and that they do reflect the broader forex market. Also, through competition, the NDD model ensures that prices are market-driven and fair. FXCM rewards liquidity providers with order flow when they provide the best bid or ask prices. The more advantageous their prices are the more order flow the liquidity provider will receive. The less advantageous, the less order flow they will receive. This efficient selection method keeps a single liquidity provider from adversely affecting your price.”