At Asirikuy we currently create machine learning strategies where a single machine learning algorithm is used to make trading decisions. This can lead to long term historically profitable trading strategies but it offers limited possibilities due to the computational cost of single algorithm testing. On today’s post I will write about the possibilities of machine learning ensembles and how they offer the possibility to greatly expand machine learning repositories without any large increase in the required computational cost. I will talk about how this only became a possibility with the introduction of the pKantuML software and why it will be key if we want to do significant increases in the portfolio size of our current machine learning repository.
–
–
In a regular machine learning strategy we have an algorithm that takes some input data, makes some predictions and then those predictions are used to make trading decisions. The calculation of those predictions is expensive, mainly because our strategies demand models to be retrained before every trading decision as a way to reduce bias in the testing process. Adding model complexity therefore increases our computational costs substantially. In ensembles instead of using a single algorithm to make predictions we take several different models, retrain all of them, make predictions and then use all that information to make trading decisions.
The key to making fast ensemble tests lies in the advances made by the pKantuML software where we are able to separate the prediction generation part of the model from the system back-testing part. In essence what we do is generate binary files containing all predictions for different machine learning models and we then use those predictions to backtest large variations of non-model related parameters (such as trailing stop types, trading hours, etc). The great advantage is that the second backtests can be carried out by OpenCL code using GPU technology, which means that billions of tests per day can be executed without a problem. The issue is of course the first part, where the model predictions are made.
–

–
However the great thing about ensembles is that they are just new systems that come from combining machine learning models. This means that if we have binary file predictions for 500 different machine learning setups we can potentially generate 124750 ensembles which means that we have expanded our potential systems by a factor of almost 250 without that costing us a second in the binary generation step. This increase in the ML space means that we would be able to explore potentially much larger system spaces since the ensemble backtests are ran in the very fast OpenCL code in the GPU rather than in the “slow” C/C++ code that is used for the generation of the prediction binary files. With 3 ensemble systems the potential expands even further. Of course this also increases data-mining bias, but we don’t worry about these since all of our data-mining experiments use testing on random data to measure for data-mining bias and avoid adding systems that have a high chance of coming from pure random chance.
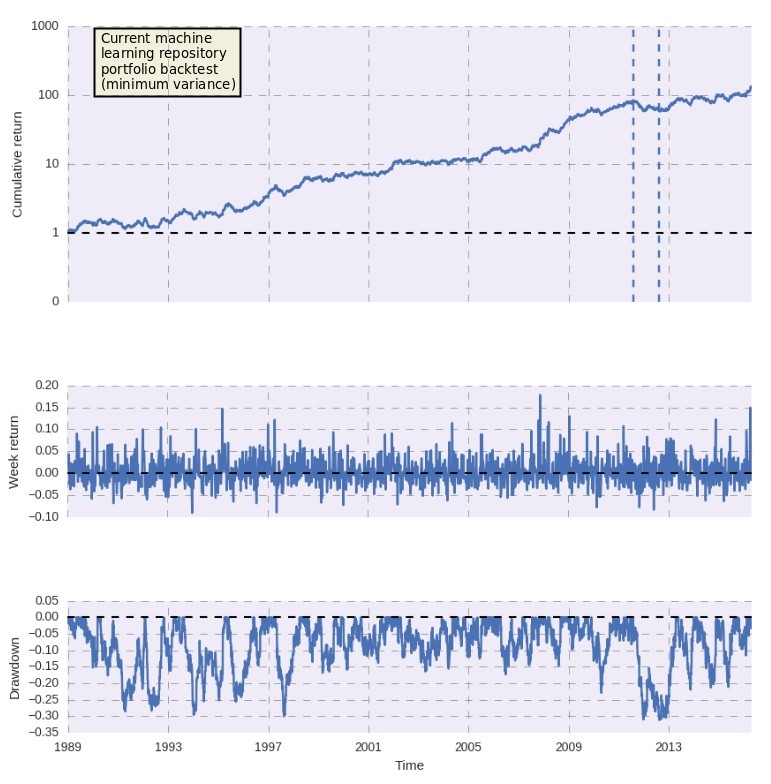
Right now a problem we’re facing is the significantly large correlation of systems generated within our machine learning experiments. This probably happens as the variability we can get from them is limited by the variations in the ML models – which are rather small due to their cost – therefore with ensembles we hope to find much more variability that will hopefully help us eliminate the significant degree of correlation that is present within each experiment, allowing us to add more systems per computational time unit invested, which will allow us to increase the size of our machine learning portfolio at a faster pace. Currently we have only 4 systems within our machine learning repository – portfolio showed in the first image above – and we would certainly hope to expand this into the hundreds of systems in the near future.
–

–
The computational implementation is close. I am presently building the modifications required into pKantu in order to allow for ensemble testing and hopefully within a week or two we will be able to star to see if ensemble evaluation really has the potential to take our machine learning portfolio building to the next level. If you would like to learn more about machine learning and how you too can code your own constantly retraining machine learning strategies please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.





I have been enjoying your latest round of blog posts, very on the money. The returns of the 4 systems shown, is that a draw down of less than 1 %, I can`t make out the readings on the pictures shown.
Hi Jim,
Thanks for writing. Glad to hear you like my posts! The drawdown here is displayed as a fraction of equity, which means that the maximum drawdown is close to 30%. Do let me know if you have other questions,
Best regards,
Daniel