After a lot of talk during the past few weeks about reinforcement learning and specifically the implementation of Q-learning approaches in trading, today I am happy to announce the release of a new software implementation for system mining at Asirikuy, pKantuRL. This new program automates the mining of reinforcement learning strategies and provides us with a speed increase of around 100,000x vs the mining of these strategies using traditional C-based back-testing using the F4 framework. Today I want to share with you some of the main features and specifications of this software as well as how it automates the entire RL process with some examples of what it is able to achieve.
–
–
Reinforcement learning can be computationally very expensive and cumbersome to carry out if you want to search through the very large number of Q-learning strategies that can be created. As we have discussed before Q-learning is based fundamentally on finding meaningful market characteristics that can be used to define market states at each different point in time and therefore if you want to find the best Q-learning approaches you need to go through a large number of potential variables to define market states. Each test requires you to first optimize the Q-learning approach through a series of iterative back-tests, time after which you should then perform a final back-test and then repeat the entire process on random data series to see how much your Q-learning approach was able to profit above random chance. Carrying out this process manually is very difficult and automating this process using a script still means you’ll need to wait approximately 1 minute per Q-learning test, and probably about an hour if you want to include a good number of tests on random series as well.
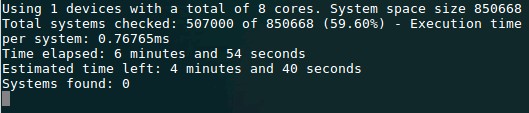
Since I coded the entire Q-learning approach we are using in ANSI C within the F4 framework it was relatively easy for me to translate this approach into an OpenCL kernel so that we could carry out this process using this much more efficient language. This also means that simulations can also be carried out using GPU technology, greatly increasing our mining potential. The image above shows you the program running on a CPU in OpenCL, where each Q-learning system test – which really also includes the 10 test training pass and the final training evaluation run – takes only 0.76ms which is equal to a 100,000x speed improvement versus what we can do using the F4 framework. This software allows us to search through millions of Q-learning strategies in a relative short period of time and it also allows us to perform the validation using random data in a reasonable time scale. Doing any of the above with regular testing in F4 would simply not be possible given the computational cost and the size of the available Q-learning state spaces.
–
–
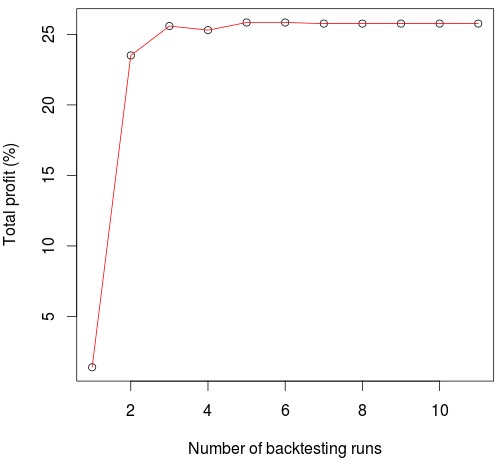
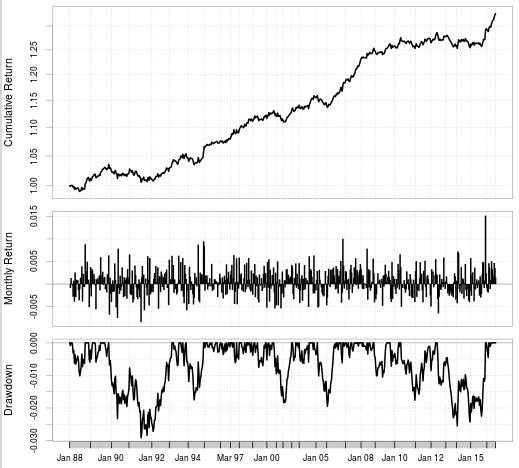
After running pKantuRL we then get CSV files with the reinforcement learning system definitions which we can then use in the F4 framework to reproduce the resulting system tests and ensure that everything runs as intended. The above shows the result of an RL strategy that was generated by pKantuRL and properly validated using random data. The first graph shows the training process which went from 1986-2010 in this case and the second graph shows the full back-test of the resulting Q-learning table using the entire data-set. As I hypothesized before using the difference with random data to validate strategies and taking only systems where this difference is high allows us to get systems that perform well in pseudo out of sample tests without the need to explicitly carry them out. This suggests that we are learning something important from the market which will continue to work as long as it provides relevant information to current market conditions.
The above also opens up the way to a new type of community mining to focus on this new type of strategy, which I will release within the next few weeks as well. Initially we will focus on mining the 1D timeframe – which is the cheapest and easiest timeframe to learn – and we will then proceed to the more expensive 1H timeframe where we can potentially find much more complex Q-learning approaches. After we mine the first systems we will also begin live trading of these Q-learning strategies which will also help us validate whether this approach to trading does offer something that our machine learning and PA approaches lack.
–

–
The first version of the pKantuRL software implementation will be available from tomorrow to all Asirikuy members. If you would like to learn more about reinforcement learning and how we have implemented Q-learning in the F4 framework at Asirikuy please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.strategies.




