Last year at Asirikuy we started our efforts to build a machine learning portfolio based on automatic system generation and community mining. Our journey in this area has not been trouble-free and we have faced several problems that have made the creation of such a repository significantly hard. Today I want to talk a bit about our journey in the creation of a machine learning repository, the issues we faced, what we currently have and how we expect to expand this path going forward. We have extracted several important lessons from this process and have further reinforced some of our previous experience in this type of endeavor. In the end we are arriving at a much more refined methodology with important technological innovations and significant room for expansion.
–
–
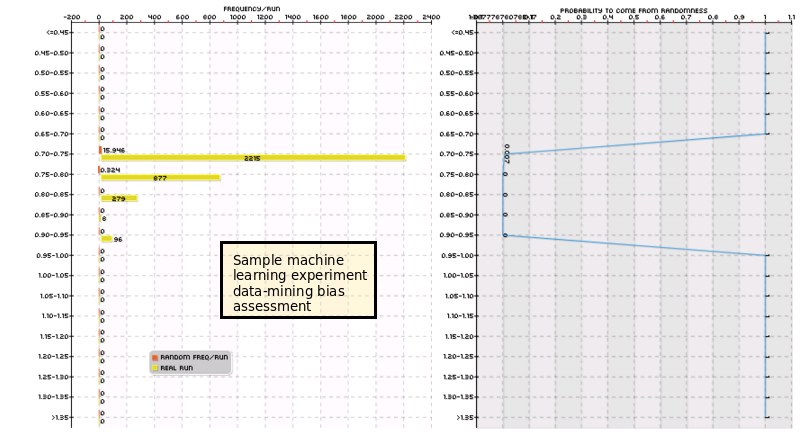
The idea in the beginning was simple. Use community mining to find machine learning algorithms, perform data-mining bias analysis and validate the strategies, then simply add uncorrelated systems to the repository and start building a large array of machine learning strategies. The repository would contain several machine learning algorithm types and would be able to tackle different symbols and trading horizons using many different types of trailing stop mechanisms. When we first started with this we were able to amass over 60 systems within the first few weeks, before we discovered a couple of important issues within our simulations that heavily affected many of these machine learning strategies. After correcting these bugs and repeating tests it was obvious that only one or two were actually worth while so we decided to start from scratch.
When rebuilding the repository we then noticed that our testing process was very slow, too slow to find any systems worth trading in a reasonable amount of time. At the moment we were performing simulations using C/C++ CPU code which meant that each simulation would take around 5-30 seconds (these are simulations were machine learning algorithms retrain before making each trading decision) so although very fast compared to things like Python it was still very slow if you needed to perform 1 million back-tests. The solution was to perform a split of the simulation process, doing the machine learning prediction part in C/C++ and then performing all the testing variations that did not require ML variations to be done using OpenCL and GPU technology.
–
–
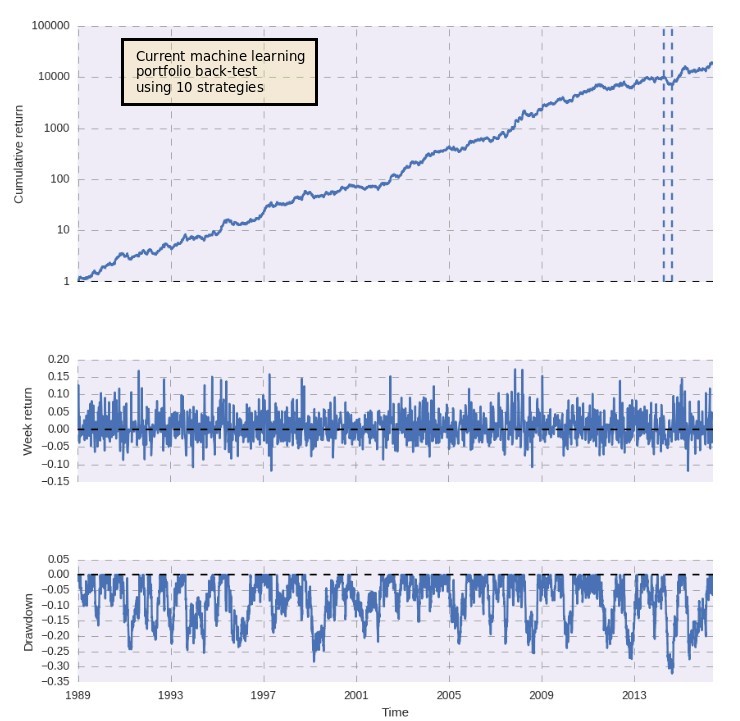
This generated a substantial increase in our processing speeds. We could now process at 1000x the speed since we could just do 100 machine learning prediction file generations and then use them to perform millions of back-tests with variations of non-ML related parameters within our graphics processing cards. In the end this allowed us to start rebuilding our portfolio, obviously controlling for the number of trials by performing adequate data-mining bias assessments using random data sets created using bootstrapping with replacement. With this process we have now reached 10 systems within our machine learning repository. The back-testing results of this portfolio can be seen in the first image above.
The problem now is that our experiments are generating too few systems because variations in system logic are scarce due to the nature of the process which restricts the amount of machine learning algorithms we can use (since these are the most expensive part of the testing process). To overcome this and allow us to have more variability, yet avoiding the generation of more ML prediction files we have decided to explore the use of machine learning ensembles which allow us to create a huge variety of ML systems by using only a small number of original ML prediction files. If we have for example 30 ML prediction files we can easily generate 432 two ML algo ensembles. This would allow us to use more expensive machine learning processes to generate the initial files without having a computational cost increase to evaluate the same number of final systems on the GPU.
–
–
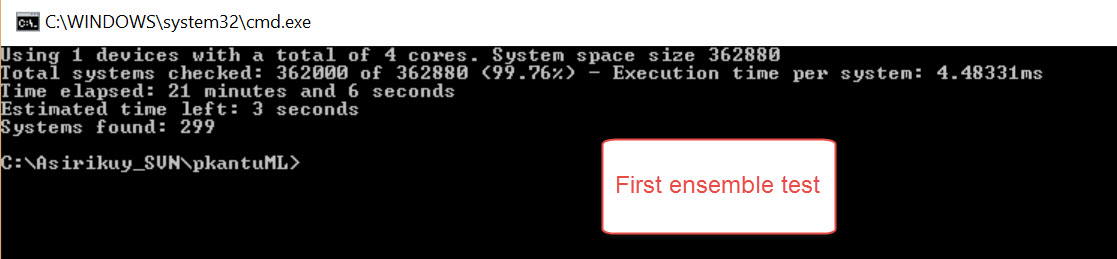
The creation of this ensemble enabled pKantuML version is now almost finished – you can see the results of the first test above – and it is already evident that there is a significant increase in the number of strategies that are found that fit our statistical criteria. It will be some time before I fully implement all the necessary changes in our community mining to allow for ensemble usage but once we do we will be able to see whether this increase in systems found is accompanied by an equal increase in the mining bias (which would completely negate the usefulness of this approach). However a lot of door open with the usage of ensembles which will hopefully lead into much more fertile mining territory. If you would like to learn more about machine learning and how you too can trade using constantly retraining machine learning strategies please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.strategies




