During the past few months I have been working on the Kantu trading system generator, a program which allows any trader to generate trading strategies that have some desired historical results. Up until now the program has achieved many of the initial goals I had in mind but a key factor that limits the applicability of this program is the limitation in the inputs (in number and description) used to generate trading rules that deliver trading strategies. Right now Kantu uses only the OHLC values of bars and through simple comparative operators creates simple or complex price patterns that generate a desired historical performance result. In order to expand the scope of this program I decided to carry out an extensive addition to the software that will soon allow traders to add custom inputs and generate systems through a potentially limitless system generation paradigm. On today’s post I want to talk a little bit more about how I implemented this and why it adds so much power to the Kantu trading software.
The initial idea surrounding Kantu – to use parameterless price patterns to generate strategies – allows us to come up with a lot of trading systems that may generate satisfactory historical results across several financial instruments but the truth seems to be that the scope of these patterns limits the possible trading solutions that can be found across the board. The main limitation is that the patterns only use OHLC information and derive patterns through an addition of rules of the form [1] (><) [2] where [1] and [2] are a choice of the open, high, low or close of any given candle available for selection. In order to expand the potential of the program it is necessary to allow the software to generate rules that go outside of this “box” by giving the program freedom to generate rules in another manner. This does not mean that you will go outside of the parameterless price pattern model, but that you will consider other possible choices. For example you could also potentially run comparisons between a candle’s middle value (middle distance between high and low) and the OHLC values, and in this manner you can generate other potential patterns that do not rely on OHLC values.
–
–
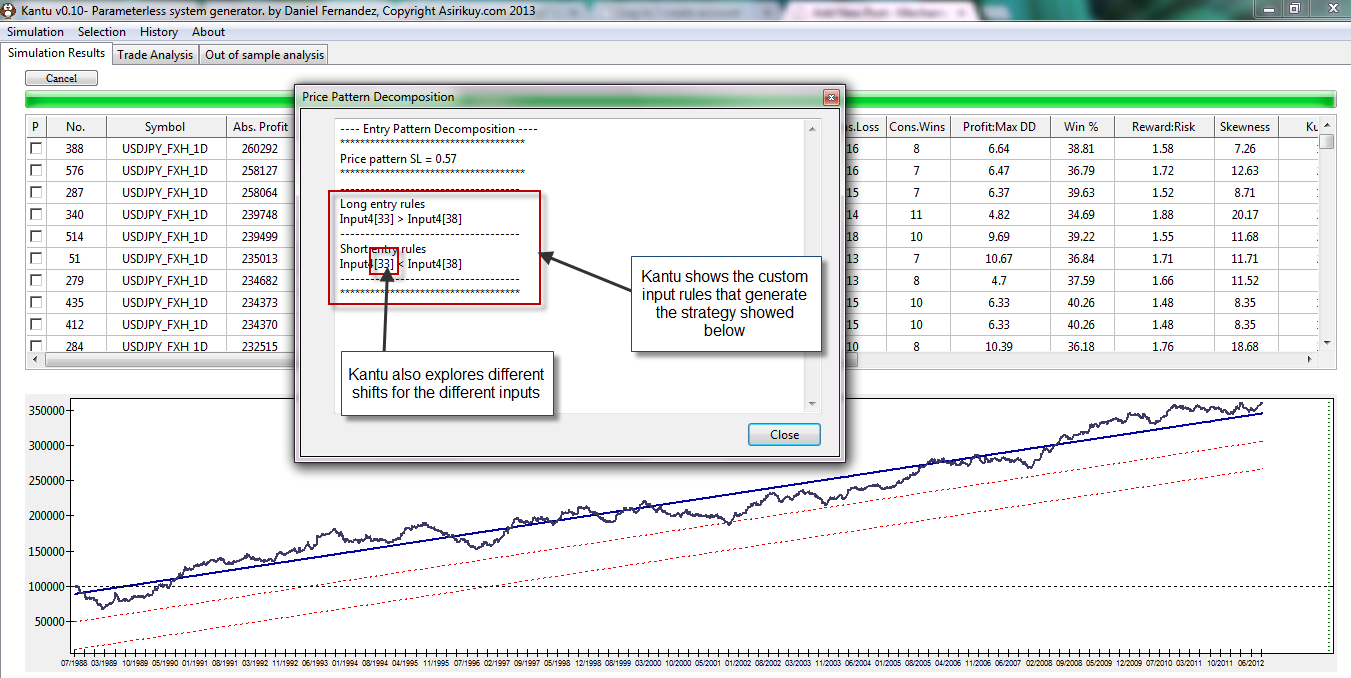
When this became apparent I decided to implement some additional rules, but after some coding it became obvious that I couldn’t code everything that users might want to use. Since Kantu already implements a powerful back-tester it also seemed unreasonable to limit the scope of the software, given that some users might also want to use things such as traditional indicators or some other type of pattern that requires some limited parameterization, such as the definition of VSA patterns, harmonic patterns, etc. In order to comply with this I modified Kantu to be able to use any type of custom input, so that users can add the inputs that they desire into the software so that they can generate systems that perform comparisons with whatever data they want. The new feature extension for Kantu allows a user to add any input to the software and generate systems that use rules based on these inputs to achieve the desired historical results. It is also important to note that this functionality is completely independent from the previously implemented features, the user can decide whether to use the regular price-pattern generation technique or the new custom inputs when loading data.
The process to do this is fairly simple. When creating data to import into Kantu – either through MT4 or through the F4 framework – the user can add whatever variables he wants to use for strategy creation within the file. For example if I wanted to use the middle point of a bar as an additional input I would simply add it as an additional column to the csv that contains the data. In order to make this process as error-free as possible I can simply add an additional parameter to the code that creates the csv file so that my input for each bar is also saved for the whole array. In The F4 framework the csv file is saved using the RecordBars EA, with this code that saves time and OHLCV values:
fprintf(fp,”%s, %lf, %lf, %lf, %lf\n”,timeString, open(1), high(1), low(1), close(1));
If I want to add the middle point, I would simply add an additional column to the csv:
fprintf(fp,”%s, %lf, %lf, %lf, %lf, %lf\n”,timeString, open(1), high(1), low(1), close(1), (low(1)+(high(1)-low(1))/2));
In this line the (low(1)+(high(1)-low(1))/2) defines the middle point of the bar which we are saving as an additional column. In this same manner I can save anything I would want to use, the average volume, the body as a percentage of the ATR, the candle range, etc. I can also have things such as the body/range ratio or even indicators such as the MA, MACD, etc. I could even add the OHLC of another pair to use multiple pairs for system generation! In fact there is absolutely no limit to the nature or amount of variables I can add. I could add 50 columns with 50 different inputs and the software can then use these inputs to generate strategies. As a matter of fact I could even add fixed constants if I want to make sure that I will be able to generate systems that make some fixed comparison such as RSI(20) > 50. One of the few limitations is clearly that – since Kantu doesn’t know the nature of the inputs – it cannot automatically generate code for the systems but pseudo code is generated as showed on the image above (full code generation is only possible right now for the price pattern functionality).
With this coding addition the scope of Kantu becomes limitless in the sense that the user can now use any given input to generate trading strategies, the limitations on the inputs – such as ensuring them to be parameterless – are the sole responsibility of the user and the software simply finds strategies with some requested historical performance that use the data that has been included within the loaded data file. My idea with this release will be to provide Kantu users with an increased ability to create strategies with whatever inputs they may desire to use. This may also shine some light into the differences between indicators/price action based systems and the differences between different types of indicators. I would also like to point out that all testing functionality – genetic search, walk forward analysis, fixed quota, IS/OS study, etc – is also available when using custom inputs.
This release is currently on the works and will be released before next Monday. If you would like to learn more about system generation and how you too can create trading systems using software please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





Although you are not required by any means I sense that you have avoided to answer my question about your previous post:
“Thanks. Still you avoided to answer the first point in that when you sample the trades in the MC you assume equal probability of these samples. As I said although you are sampling with equal probability this is NOT equivalent to the samples having equal probability of occurring in the market. Before you can average statistics you must prove that ALL these samples have the same probability of occurring in the market. Unless this is true, the fundamental assumption of MC is violated and the results may be worthless.”
In the case of the MC simulation you have made a fundamental statistical mistake by assuming that all possibilities you sample have equal probabilities and as a result you provided meaningless numbers.
Now as far as the Kantu project it is highly possible that you are creating a curve-fitting algorithm by adding possibilities to assist the program. Ability to code does not transform directly to profitable ideas. What method do you propose for checking the Kantu systems against curve-fitting? You must agree that this is a reasonable question to ask and not merely an attack against you as this is not the intention here.
Hi Joe,
Thank you for your post :o) Sorry, I hadn’t seen your comment on the previous post.
I don’t understand very well what you mean by “ALL these samples have the same probability of occurring in the market”. How do you know the probability of a sample occurring in the market if you cannot predict future market conditions ? Our systems are tested to completely lack any meaningful serial correlation, so in this sense any possible resampling that complies with the orginal distribution of returns that also lacks serial correlation is an equally plausible candidate. Do you mean something else ? If so how do you measure it ?
Well, what do you mean by curve-fitting? If you mean the imminent failure of systems under unseen market conditions due to an over-adjustment to past market conditions I would say that there is no 100% effective way to tackle this because there is no knowledge of the future (any system can fail right after being designed, there is no way to guarantee this will not happen). To reduce it I would say that the best solution is to
a) use a large set of data for system creation (so that you cover an ample set of market conditions)
b) try to develop systems that work across several different symbols such that the number of market conditions you cover is even larger
c) design systems with no trade chain dependency
d) design systems with as little broker dependency as possible (same results across different broker feeds).
However there is no absolute safe guard against this, if market conditions change significantly a system will fail, no matter how much you protect yourself because well, you are designing with some hindsight and you cannot know the future. The best thing you can do is design systems that cover lots of market conditions and make sure you design it so that dependency is not an issue. Alternatively you can also develop a system design methodology – which ensures your system creation process has been robust to curve fitting in the past – by using Kantu’s walk forward testing abilities. Definitely Kantu can be used to generate strategies that will fail with a high degree of certainty, it all depends on how it is used by the end-user. As I have said before this is just a tool that seeks to provide the user with as much possibilities as he/she wants, whether or not the user is successful will depend on how they tackle the problem and whether their approach is sound. Kantu is not a holy grail.
I would also like to point out that these additions do not necessarily lead to “more complex” strategies, they just allow you to implement custom inputs that aren’t necessarily either more in quantity, or more complicated. So this is just a feature that adds possibilities but it doesn’t mean that you need to use it in A or B way, it just means that you now can do more things. I hope this answers your question :o)
Best Regards,
Daniel
Hello Daniel,
Impressive improvement. Kantu for me is perfect finally!! I will invest a lot of hours playing with it :)
Hi Daniel,
Thanks for your answers. I will raise my concerns below
a) use a large set of data for system creation (so that you cover an ample set of market conditions)
There are arguments in many respected quant websites that using data beyond 5 years is waste of time because markets have changed. They present all sorts of studies for that argument.
b) try to develop systems that work across several different symbols such that the number of market conditions you cover is even larger
But if they work for 20 symbols for example, you can always find another 20 symbols for which they do not work. Usually the winning results are presented.
c) design systems with no trade chain dependency
Your systems are long-sort symmetric so there is trade dependency in the sense that every long is dependent on a sort and the other way around. Can you be more specific? How do you measure that? I do not think serial correlation of equity curve is a good measure.
d) design systems with as little broker dependency as possible (same results across different broker feeds).
I agree with this. This is a good suggestion in the case of forex especially. Not too many deal with this issue so you deserve a lot of credit here.
Hi Joe,
Thank you for your post :o) Let now answer your comments:
a) Yes, I am away of this research but my personal research – for our particular system types – show otherwise. For example if I run a walk forward analysis on the EUR/USD with a 5 year system generation period length I get much worse results than if I use a much larger (+7) set. In fact the best results come from using the largest generation sets. Although for some systems the above 5 year threshold might be true I have found this to be false for my strategies (walk forward analysis of randomly chosen 5 year periods with several out of sample lengths across the past 25 years have showed this).
b) I think that you’re good if you find systems that work across all the most highly liquid instruments. The less liquid an instrument the more efficient it is (according to what I have been able to research on the subject). If I find a system that works across all highly liquid instruments I would be happy with it.
c) My systems are long/short symmetric (in the sense that the amount of longs and shorts are always controlled to be very similar) but this doesn’t mean that every long ends with a short signal, etc. The systems have exit criteria (SL, TP, internal exits) that allow them to exit without necessarily creating an opposite trade (although opposite signals also generate closes). My avoiding trade chain dependency I mean that the system’s results should be completely independent of system starting time.
d) Thank you for your comment :o) I do believe this is an important matter!
Thanks again for posting Joe,
Best Regards,
Daniel