Last month I posted about the great improvements that we were likely to achieve thanks to the implementation of machine learning mining software (pKantuML) that used an OpenCL/C hybrid process for the mining of machine learning trading strategies. After spending a lot of time building and testing the software plus doing all the server side implementations for the cloud mining and the processing of cloud mining results today I am glad to say that we now have a fully functioning machine learning cloud mining operation using the power of mixed OpenCL/C calculations. On today’s blog post I want to talk a bit about what we have achieved, how this will evolve and why this will bring a significant level of diversification to our current trading operations.
–
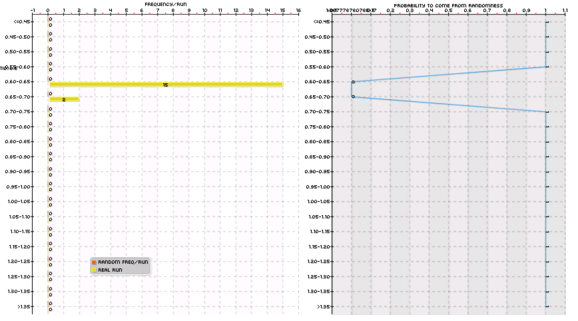
–
The idea with pKantuML is to take advantage of GPU simulations to mine machine learning trading strategies, however since the ML part cannot be easily translated into OpenCL code -especially in a way in which results are the same between OpenCL and C/C++ for live trading – we decided to generate all the needed ML predictions within our C/C++ tester and then use these generated prediction files to perform massive amounts of simulations in OpenCL code varying things that do not depend on the machine learning code (such as the filtering hours, stoploss values, trailing stop types, etc). The idea is to do a small amount of computationally intensive work in C/C++ that can then be expanded greatly by using OpenCL. The result is a process where we can simulation millions of machine learning strategies in just a few days, a process that is three orders of magnitude faster than doing everything within our tester’s C/C++ code. Using GPU to perform the OpenCL part we can get even greater gains, thanks to the immense and cheap processing power of these cards.
Of course the entire idea was to then implement the above within a cloud mining setup where we could all contribute to the same set of machine learning experiments in order to properly validate the results by doing data-mining bias assessment experiments using data generated using bootstrapping with replacement. The first picture above shows you the first experiment that was finished using our cloud mining setup. The runs generated on random data showed absolutely no systems with Sharpe ratios >= 0.6 while the real data showed 17 systems from which one of them was added to our repository (as correlations between the 17 systems were significant). This has been the first system addition to our trading repository but it will certainly not be the only one.
–
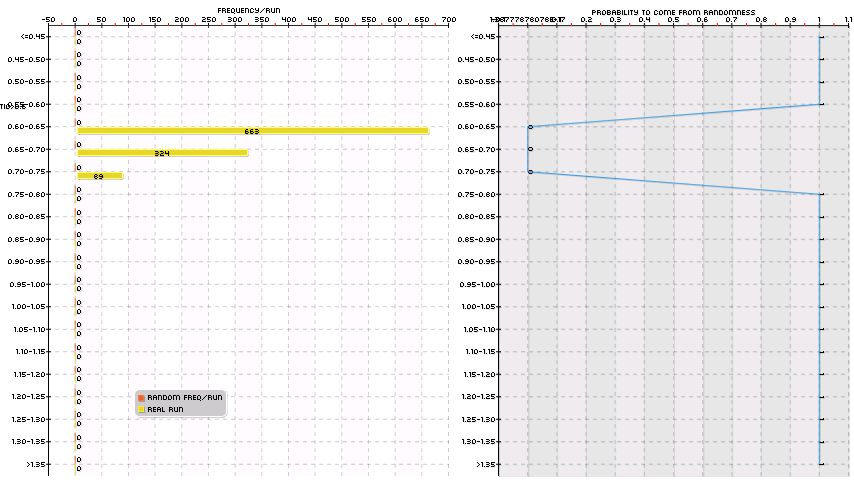
–
The second picture in this blog post shows the results of another experiment that has a larger space – searches around 80 million systems – on the USD/JPY. This experiment has not been finished yet – it still has too few generation runs on bootstrapped data – but the very interesting thing is that it contains more than 1K systems for additions. Many of these systems trade on different hour filters using various different trailing stop mechanisms so we will certainly be able to find several clusters of uncorrelated strategies which will yield a much more varied set of additions. We should be able to add at least 20-100 systems from this experiment to our ML trading repository.
The last test within this process is certainly to take the finally added systems and run them through the regular C/C++ tester in order to ensure that all the data has been processed correctly and that the final statistics for the system are indeed like those that came out of the process (otherwise we wouldn’t be doing anything useful!). The last picture within this post shows the equity curve of the last system that has been added to the repository. The simulations confirmed that the statistics of the strategy are the same as those obtained through the OpenCL simulation process so this indeed confirms that the entire process is being carried out in a reliable manner (simulations across the different software implementations are correct). This coherence in the simulations was the hardest thing to achieve, with one of the most frustrating bugs I have ever found (you can read more here).
–
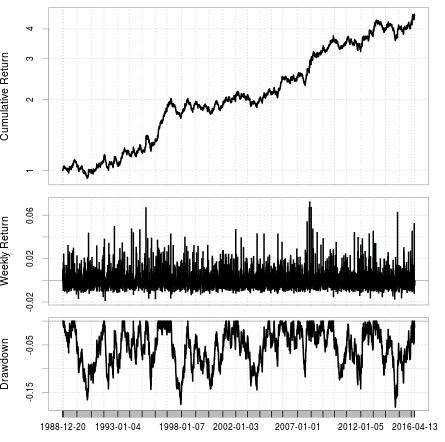
–
The next step in this quest is to continue the generation process and start trading these ML systems live in a portfolio when we have 10-20 systems. After this the next step is to greatly expand the space by doing ML ensembles instead of doing a simple ML algorithm per system. The advantage of this is that the generation of the prediction files is already implemented so we can greatly expand on the number of tested strategies in the openCL code without having to expand on the costly C/C++ code generation part (since you would just be combining sets of predictions). This will mean that we will be able to expand our search space to billions of systems per day without a very considerable computational cost. I am reserving this step for later as we first have to more thoroughly exhaust the single algorithm part. However expanding the process to N machine learning ensemble systems should be an easy task with what is already implemented.
Our journey in ML has just started and although we have already faced many obstacles we have learned many things and continue towards the development of machine learning cloud mining and automated machine learning system generation. If you would like to learn more about machine learning and how you too can code your own ML systems using our programming framework please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.strategies




