When you go into the world of automated trading system development one of the first problems that you need to tackle is how to design your trading systems so that you will have profitable trading results going forward, into the future. Since the future is unknown there is no crystal clear answer to this question but we often come up with intuitive ideas that lead us into the assumptions we use to design our strategies. First of all we assume that the future will resemble the past somewhat and this is then extended to imply that systems with profitable historical results should also give profitable results going forward (what all trading system creators share to some extent). However it is difficult to tackle the fine points of the above assumption and to proof that they have at least worked in the past to some extent. For example what does it mean “to be profitable” ? What historical results do you use ? Can you assume that a system that trades profitably on one instrument will continue to work on that one or do you need to have historical profitability across many symbols and – why not – markets ? On today’s post I would like to touch on my research on this matter and share with you some evidence that points into “what works” and what doesn’t in the search for out of sample profitability. http://debashishbanerji.com/consciousnesswriting/living-laboratories-of-the-life-divine/ Obviously there is still a ton of work to be done, so these are just my first observations.
To evaluate the difference between in sample and out of sample results we first need to create a software implementation that allows us to generate as many strategies as we want and which also allows us to filter the strategies by some performance measurement and then show us the results of the strategies across another period (the out of sample). We can then see how the statistics of our strategies in the in-sample match the out-of-sample and if the strategies with good out-of-sample results share something in common that can be determined from the in sample results. We can then see if the implementation of some filter can improve the health of our chosen strategies (which are always generated randomly so they are different) and we can then cross-validate the above by testing whether this methodology yields similar results on other symbols. A few weeks ago the above tests would have been impossible for me to carry out but now – thanks to the Kantu implementation – I can now randomly generate thousands of different strategies and test correlations between in sample and out of sample performance.
–
–
The first test I carried out was to generate a set of 100 random strategies which are all profitable and symmetric (because most people would never choose to trade a losing strategy or an asymmetric one in Forex trading) and then I looked at what the out of sample results were like in a random population. For this initial test I used the 1985/2005 period (close to 20 years) as an in sample and then I looked at the results in 2005/2012 as my out of sample. The results showed that – as you would expect – most strategies are in fact losers in the out of sample period while some terrible in-sample performers (just a little in sample profit) turned out to be brilliant performers in the out of sample phase. This would be expected as some systems that are terrible losers suddenly have market conditions change to adjust their particular trading mechanics, but since there is no way to select a losing system that will become a winner without hind-sight then it is not useful to analyse these cases. Overall the results are what you would expect from such a population. Repeating this analysis with higher random sample sizes or with other symbols yielded very similar results.
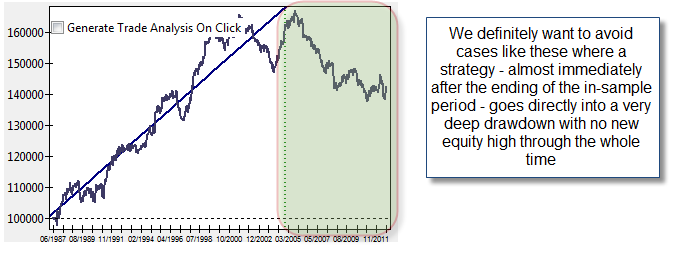
After this I then started to look at how equity curves I would have deemed “fit to trade” did during the out of sample period. To do this I looked at the in-sample statistics and looked at things such as linearity and the system quality number (as defined by Van Tharp) as well as things such as the risk to reward ratio, the winning percentage, etc. To my surprise it seemed that many strategies that were fit in the in sample crashed heavily in the out of sample. Despite the fact that the equity curves were pretty and stable in the in sample there was something going on in the out of sample that crashed the trading systems, the strategy was for some reason not robust enough to tackle future market conditions despite its previous performance. With this in mind I then decided to look at the systems that looked good in both the in and out of sample results during one of these random runs, attempting to find what they may have in common.
–
–
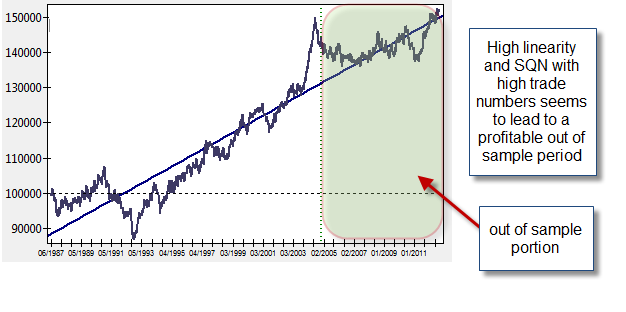
What strategies with good in-sample results and good out-of-sample results have in common is that they have both a high number of trades and a high equity curve stability during the in-sample testing. The strategies that do well here seem to have more than 2000 trades, very high linear regression R^2 coefficients and system quality numbers above 2. It is also curious that if you change the size of the in sample period this “trade number” requirement doesn’t seem to change with systems still needing about 2000 trades to show better out of sample results. For example the same test from 1986-2000 has the exact same characteristics. By filtering strategies from random runs with these characteristics I was able to decrease the probability of an unprofitable out of sample result from nearly 80% to about 5% (about 50 out of every 1000 systems that passed through the filter). In the case of a 1986-2009 test with 2009-2012 as an out of sample period I was able to decrease this even further to 1%. These suggests that using the above mentioned criteria one can build a trading strategy that is likely to show some profitability during the next 3-7 years of out of sample testing, or at least these demonstrates that this was the case in the past.
It is also worth noting that the above does not imply that the problem is solved, on the contrary the above research opens up much more questions than it answers, also needing much more testing across other symbols to validate whether the results are true for different types of instruments. What I hoped to show is that there seem to be some significant correlations between in-sample and out-of-sample statistical results for trading strategies (at least the parameter-less price pattern systems created using Kantu) and that researching this can help us get an idea of what the “best method” actually is to device a trading strategy to tackle future market conditions. Finding what statistical characteristics should be maximised and what characteristics we should not worry about are one of the most important questions within this area of research.
If you would like to learn more about Kantu and automatic system generation please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general . I hope you enjoyed this article ! :o)





Another method of increasing out of sample performance is to use detrended returns i.e. returnSeries – mean( returnSeries ). This is talked about in detail with many other methods to data mine for trading strategies in ‘Evidence Based Technical Analysis’ a great book…
What happens if the system is based on trend-following and the trend is removed?
Hi Rick,
I ran some tests of behaviour under these conditions, what happens is that the system generally goes flat (losses a big part of its edge) but it doesn’t go into a huge drawdown. However once you create a new system after a year you will already take into account these conditions and the performance under non-trending conditions will improve if they continue. I hope this answers your question :o)
Best Regards,
Daniel
To train trend strategies you will need the in sample data to have both positive and negative trends, in which case detrending that series will only remove the skewness, not the actual trends….
“returnSeries – mean( returnSeries )” This is centering, not detrending. It will produce negative prices in most cases. Again, making any changes to a series causes backtesting results that are not real. Again, if you are designing trend-following systems, removing the trend is not a reasonable thing to do.
Agree with Ric; if you cant trade the de-trended prices in real life; then what is the point.
i.e. you can detrend the price by substracting the moving average from the price. It will make a nice stationary timeseries; and mean reversion will make you a millionnaire. but can you trade it?
[…] always, please read it all to get the […]
Good work, keep it up.