It is no mystery that not all currency pairs are equally hard to trade systematically. Answering the question of which pairs are easier to trade from an algorithmic perspective is quite important as focusing on things that lead to more inefficiencies can imply a better probability to achieve a higher profit. Today I want to talk about which currency pairs are the easiest to trade mechanically, how I have found this information and why I think currencies are grouped in this manner. We will first go through what it means for me that a symbol is “easier to trade” and we will then talk about trading difficulty according to this definition.
–
–
From the time when I started designing automated trading strategies it became evident that it was far easier to produce systems for some symbols than for others. When manually creating automated trading systems it was already clear that creating systems for the EUR/USD was far easier than creating systems for any other symbol, no matter if I wanted to exploit trends, ranges or other types of commonly defined trading behaviors. When I started experimenting with neural network strategies the first systems were all EUR/USD strategies and a few years would need to pass before I reached success in the creation of neural network strategies for other symbols. It is no coincidence that my number of blog posts and magazine articles about EUR/USD systems is far greater than for other symbols, it was simply because – for whatever reason – everything was simply easier to produce for this pair.
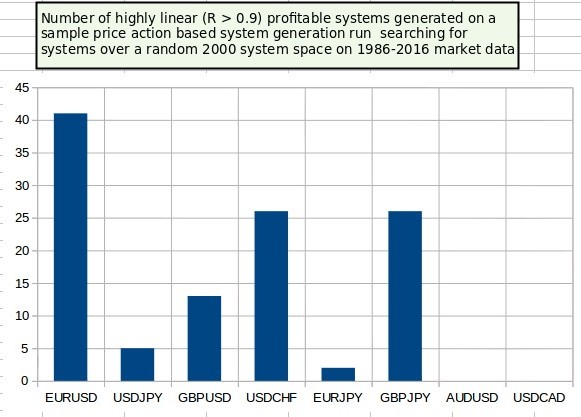
When I started moving to automatic trading system creation in 2013 it was evident that the trend remained the same. Although when using powerful data mining and advances in our understanding of machine learning we were able to find very good systems for other symbols (mainly the USD/JPY, GBP/USD, USD/CHF, EUR/JPY and GBP/JPY) it was clear that the number of high quality systems produces on the EUR/USD was still far greater than for every other pair. No matter if you’re talking about manual algorithmic system design, automatic price action based system generation or machine learning strategies, the EUR/USD wins each and every time in the number and quality of the trading systems that can be found.
The mystery deepens when you consider the symbols where we haven’t been able to find anything usable. For example every attempt at price action based or machine learning based system generation for the AUD/USD or the USD/CAD (or any other AUD or CAD pairs) has failed bluntly. The fact that we haven’t been able to find any systems for these pairs that can provide profitable and highly stable 30 year back-tests points to some fundamental difference between pairs containing CAD or AUD and other Forex symbols. Furthermore crosses like the GBPCHF, EURGBP, EURCHF and EURCAD have also been basically barren despite our biggest efforts to extract some long lasting market inefficiencies. Why is it that extracting something from these pairs seem so difficult?
–

–
There are several potential explanations. The first that comes to mind is costs -since the EUR/USD and USD/JPY are the cheapest to trade -but when you consider that expensive pairs like the GBP/JPY and EUR/JPY are able to give high quality systems over 30 years we start to see that costs may not be a big part of the picture. Furthermore pairs like the AUD/USD have relatively low trading costs compared to something like the GBP/JPY and still there are no high quality systems to be found on the AUD/USD through all of our efforts and lots on the GBP/JPY.
Another thing is to consider statistical measurements such as null hypothesis tests for random walks and entropy (which I have discussed before on this blog) but in the end what we find is that the number of systems that we are able to find over 30 years is unrelated with both entropy and random walk hypothesis testing. For example the USD/CHF has the lowest 30 year entropy value and yet the number of systems that you can produce on this pair is far lower than those that you can produce on the EUR/USD, although this last pair has a significantly higher level of entropy.
In time I have also been tempted to consider volume as a plausible explanation, since the only trend that seems to make sense in the number of systems found on the EUR/USD, GBP/USD, USD/JPY and USD/CHF is one that follows pair volume. The EUR/USD produces more systems than the USD/JPY and GBP/USD combined, just as much as you would expect when comparing long term average volumes for the three pairs. The trend falls apart when you consider the EUR/JPY and the GBP/JPY which have far lower volume than the AUD/USD. However my hypothesis is that the EUR/JPY and GBP/JPY values are actually derived majorly from what happens on the EUR/USD, GBP/USD and USD/JPY, reason why they have so many inefficiencies. The fact that their particular volume is low but the “related pair” volume is so high may explain why despite the lower volume they contain so many well-behaved systems. In the case of the AUD/USD, USD/CAD and their related crosses I hypothesize that this volume is never high enough or hasn’t been high enough for enough time.
–

–
Perhaps what determines whether something can yield 30 year historically profitable systems is whether the individual full currency volume – which I am defining as the sum of all pairs that trade each one of the two currencies in a pair- has been high enough for a significantly long period of time. In the case of pairs like the EUR/JPY this may be high enough while for CAD and AUD pairs it might not be above a given threshold. Of course the answer might also be that we haven’t been looking hard enough or at the right places – that there is an “Eden” of AUD and CAD systems somewhere along the possible system space – but even if such an oasis exists it is very particular and hard to find. The fact that machine learning and price action based systematic mining has failed to yield any results is restatement to the “rareness” of this region, if it in fact exists.
If you want to design or find algorithmic trading strategies in Forex trading I therefore suggest you start with the EUR/USD where I am sure you won’t have hard time finding robust long term inefficiencies. If you would like to learn more about system building and how to create your own strategies automatically please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading in general.





yep, I have seen the same. My best strategies are developed on EURUSD, and also have found some things for USDJPY and GBPUSD but nothing for AUD..
Great post as usually Daniel, thanks so much and great to hear about your findings! I almost completely agree, for me the ranking for systems generated on SQ (but also almost any other platform like FSB, Adaptrade) that have a R^2 > 0.95 and a return/dd ratio > 15, on 29 years of data and on 21 pairs are: EURUSD, USDCHF, AUDCAD, GBPJPY, EURCHF, EURJPY, USDJPY, GPBUSD. On all the other remaining pairs I have hardly found even 1 system that fulfills the above criterias – and I am already generating systems for years just like you. I´ve found like 2 or 3 on EURCAD, but they have had a VERY high DMB and hence had been curve-matched and did fall apart by even just changing a few parameters. In general I also noticed that the more systems you find for a pair, the less likely is a high DMB on that pair for the found systems overall.