During the past few days I have been talking about trading costs and how examining real market structure and portfolio composition can help you decide how to trade in order to have the lowest possible costs. However there will always be times where there will be spread increases and a decision to trade has to be made relative to the new increased spread costs. On today’s post I will talk about the possible solutions that I have come up with to tackle this problem some of which are a direct compromise between the reduction in trading costs and being able to take advantage of all possible trading opportunities. We will talk about some approaches that can be taken, what the consequences of the different solutions are and what sort of mechanism would make sense given different spread increase distribution assumptions.
–
–
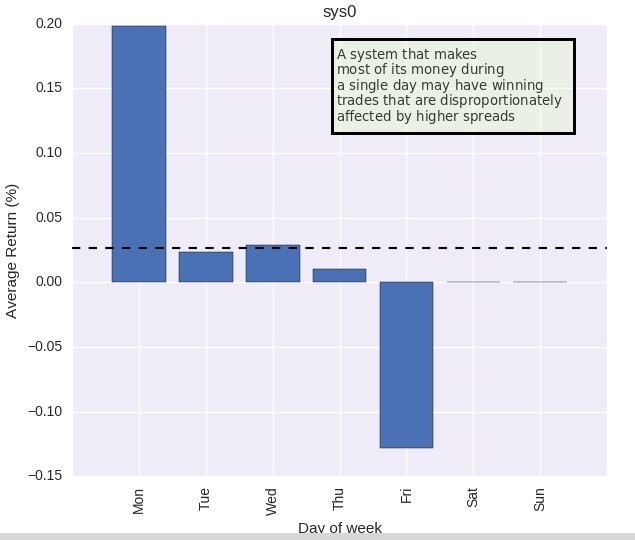
Imagine that you have a system that has a long term track record where positions have been won 19% of the time with a reward to risk ratio of 2, the strategy trades every day at the same hour and there are times when the trading hour coincides with a news release and there is a significant spread increase. The strategy normally trades at a spread of 2 pips and when there are news the spread increases to 5-50 pips. How would you decide when to trade and when not to trade when the strategy faces this scenario? Is it better to never trade when the spread increases beyond a given threshold? Is it better to just trade every time and assume the spread increases are part of the long term costs of trading the system?
If you decide to always trade then you will face an increase in the average cost per trade. If the strategy took 4000 trades and 5% of those systems faced a spread increase of 20 pips then that means that total costs would go from 8000 pips to 11600 which is a 45% increase in trading costs. You could certainly simply deal with that by increasing the average trading cost in your simulations by that amount, which would correctly implement the reduction in overall long term profitability due to the additional spread costs – which would let you evaluate the long term consequences – but which would inevitably distribute this cost homogeneously, making conclusions based on trade-by-trade analysis difficult to achieve. Under these assumptions a strong enough mining mechanism might still be able to create strategies that exploit the assumption of below average spread during these higher-spread times, therefore making the assumption of higher average costs in fact wrong.
–

–
The next solution is to decide not to trade when the spread is above the spread in the simulations or another hard threshold. Say you face a spread of 2 pips on average in live trading but you do your simulations with a spread of 4 to account for historical fluctuations in spread and some slippage, you will then avoid doing any live trading where the spread goes above 4. The main problem with this is that you will be inevitably missing some trades. If your winning trades are clustered around times of high spreads this may inevitably ruin your trading strategy as it may more profoundly affect the winning side of your trading equation. This is particularly bad if you have systems with a high reward to risk ratio and low win rate since in this case affecting winners more might make the entire strategy unprofitable.
Another potential fix is to weight your decision not to trade depending on the spread deviation. This means that you would introduce something like an exponential function where the probability to trade approaches zero as you go into higher spreads. The probability to trade will always be 1 when the spread is at or below the back-testing spread but when it faces a higher value you will “roll the dice” to decide whether to trade or not. This has the advantage that it does not treat a spread of 5 the same way as a spread of 20 pips and you will only decide not to trade when the spread is really high while lesser spread increases will sometimes cause you to miss trades and sometimes not. This way of tackling the spread issue is fairly dynamic but again suffers from problems if there is clustering of high spreads around winning trades.
–
–
If you’re not confortable with the notion of cost-probability based trading you can instead decide to weight trades to compensate for variations in the spread. So say the spread increases from 2 to 10 pips, you will then trade 1/5 the size to compensate for the additional spread cost, this ensures that you will compensate for trading costs such that a trade that paid 5 more times in terms of spread will not be more expensive. This means that in theory you will be taking each and every trade but of course you will be taking some trades with far less weight and some trades may have such a high cost that you may not be able to trade them because they will fall below your minimum possible lot size. Again this mechanism fails to work if the spread increases pool around winning trades.
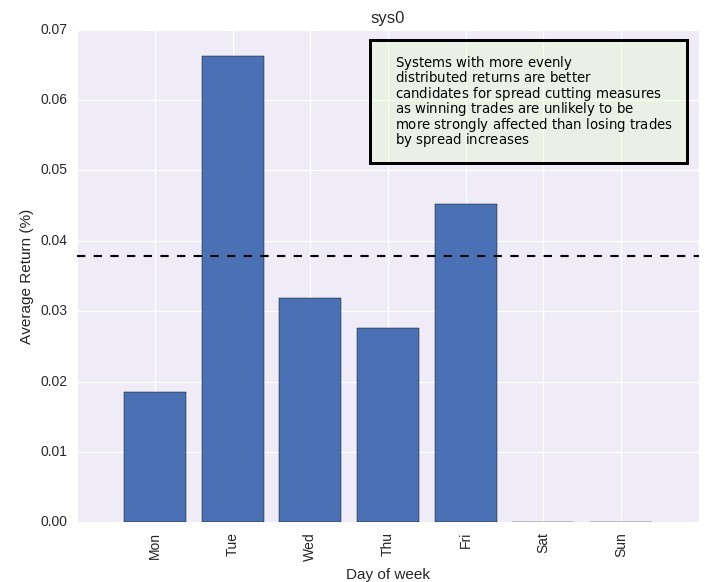
Although all the above mechanisms offer ways to deal with spread costs, all of them – except the higher simulation cost – have in common that increases in spread costs must be somewhat randomly distributed within the data and not affect winners much more than losers. Ideally a system creation process should avoid the possibility of winners being disproportionately affected by higher spreads. In either case gathering data about how spread increases affect a strategy is important to understand how spread increases may be objectively handled. If you would like to learn more about trading system design and how you too can build and back-test your own trading strategies please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.strategies.




