Since early 2010 I have worked arduously in understanding how to develop machine learning based trading systems for the Forex market that can deliver historically profitable results in Forex trading and have a good chance of being good performers under live trading conditions. Through this journey I have explored many different machine learning algorithms, libraries, trade management and input/output structures with the hope to find some general rules that can serve as guides for those looking to develop successful trading systems using machine learning. On today’s post I want to share with you a summary of the main conclusions of this search up to this point, how I started in the world of machine learning, what I initially found out and what the current state of my searching process is.
–

–
Why machine learning? My journey into the world of machine learning strategies started in the same way as it starts for most traders. I was searching for a trading algorithm that could adapt itself in some manner to evolving market conditions without any sort of parameter re-optimization and the most potentially rewarding way to do this was to come up with a strategy that using some sort of learning algorithm could extract patterns from the market and then find inefficiencies successfully on its own. A system that could learn, trade, rinse and repeat.
Initially my experiments trying to imitate results from the academic literature in machine learning failed bluntly, I could never obtain a long term historically profitable result that was anything but pure over-fitting. I invite you to read this post to learn more about why the academic approach to machine learning system building is wrong. As a matter of fact success only started to come when I started to do something that the academics never do, constantly retraining my machine learning strategies. My first useful systems came from constantly adapting neural network strategies on the EUR/USD daily charts, using first a very complicated strategy that used close prices and a comparison between NN predictions to draw a final prediction useful for live trading (Sunqu) and then systems using returns (Paqarin) and images to draw predictions (Tapuy). All these systems had in common a prediction of directionality for the next timeframe as outcomes on the EUR/USD daily timeframe and a constant retraining of the machine learning algorithm on every bar using a given set of past historical data (a moving window of training data). Finally all these systems were put together into what I called the “AsirikuyBrain“.
–

–
From the above some things were already quite clear to me. First of all you need to have a system constantly retrain its machine learning algorithm if you want it to be successful. The key is that, constant changing of the algorithm’s characteristics to tackle different market conditions which manifests as a need to constantly retrain the algorithm. It is much easier and less prone to over-fitting to create an algorithm that constantly retrains to match a small set of presently active market conditions than to make an algorithm that encompasses a huge amount of trading conditions. The big lesson from this first part was this, constantly retrain.
The above work was done exclusively on neural networks and using the FANN library. Later on – when we moved to F4 in Asirikuy – I changed my favorite machine learning library to Shark which provided a whole new range of machine learning methods that were now accessible to me for the building of trading strategies. This is when I started exploring Nearest Neighbor, Linear regression, linear mapping, random forests and support vector machines for the building of strategies. This gave me a lot of information about what algorithms were expensive or cheap computationally and what configurations gave the best results. Overall I always found regression based machine learning to work much better than classifiers and in particular neural networks, random forests and linear regression algorithms always gave me the best results. At this point I also started working with AlgoTraderJo (a member of our community) to explore the world of machine learning systems. He has also has a thread on ForexFactory where he goes into a lot of depth into some of his own and some of our shared machine learning experiments.
Up until this point my problem had always been to find something to move to lower timeframes and to move beyond the EUR/USD. I had never achieved it with my initial experiments and I was only able to get to this point when I realized that the output structure I was using was not ideal. The biggest breakthrough during the past 2 years has been to use actual hypothetical trade outcomes as the outputs of a machine learning method. Instead of attempting to predict whether the next bar is bullish or bearish I changed the algorithms to predict whether a trade entered on the current bar that is handled using a given trailing stop mechanism will be successful or not. This generated a sort of generic framework for the design of machine learning strategies where the potential number of machine learning strategies was easily expanded by changing the trade management methodology or other characteristics of the ML method, such as the number of examples used for each training, the number of inputs used, the types of inputs used, etc.
–
–
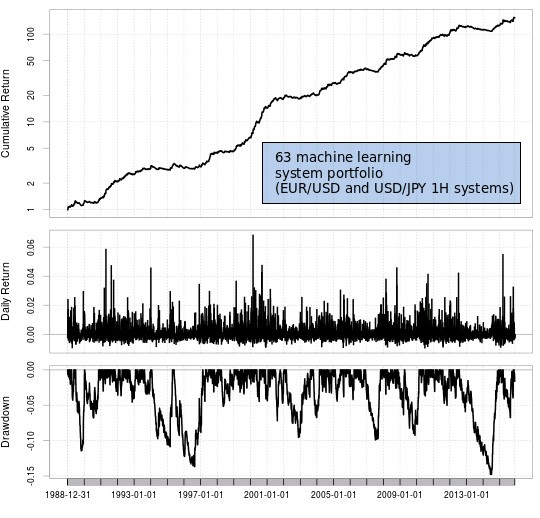
The above solved the problem of finding historically profitable systems on the lower timeframes and on symbols beyond the EUR/USD but there was still an important problem hiding behind the curtains: data mining bias. Since the search for machine learning methods carries with it a big amount of potential bias due to the repeated use of the same data it is necessary to establish some statistical method that can test whether systems are or are not simply the result of the mining method. This lead to the development of our Asirikuy cloud mining machine learning effort which currently uses computational power from several of our community members to mine machine learning strategies. Using this we have so far created a portfolio with more than 60 uncorrelated machine learning strategies that we are currently live trading within our trading community.
Up to this point I think we have established a rather solid methodology for the searching and finding of machine learning strategies at Asirikuy but there is certainly a lot still to explore in the world of machine learning. On my next post I will go into more depth on what we are planning to do next, what might significantly improve our current searches and how we plan to increase the speed of our cloud based machine learning. If you would like to learn more about machine learning and how you too can create your own strategies based on constantly retraining adaptive algorithms please consider joining Asirikuy.com, a website filled with educational videos, trading systems, development and a sound, honest and transparent approach towards automated trading.





“Instead of attempting to predict whether the next bar is bullish or bearish I changed the algorithms to predict whether a trade entered on the current bar that is handled using a given trailing stop mechanism will be successful or not”
How would you describe it mathematically ?
Hi KL,
Thanks for posting. If you’re interested in learning more about the details about how these systems are coded I would invite you to join our trading community (asirikuy.com) where you will have access to the full source code of all our ML trading strategies. You will then be able to see exactly how these criteria are coded and expressed mathematically. Let me know if you have other questions,
Best Regards,
Daniel
Very interest your effort of exploiting machine learning for trading. I would like to connect to your trading community. I I have spend a lot of time for developing committees of neural networks for trading in forex market. I experimented using different outputs (more than 100). What I have found is that the outputs which are not related to a specific time in future arre better. For example, predicting the highest or lowest within a specific time forward. I concluded that a trading system is more profitable when combining more predictions (outputs), especially using committees. Regarding the amount of data required for inputs depends on the number of inputs, the number of nodes and layers. Thanks
Hi Nikitas,
Thanks for posting. Your observations regarding large numbers of outputs are really interesting and in line with some of our latest observations. Your comments on the type of outputs to use are also in line with the things we have observed. Of course feel free to join our community whenever you like or to post more questions either here or through the contact form on our page. Thanks again for writing,
Best Regards,
Daniel